Articles
Введение
Постоянное развитие беспроводных сетей заставляет сетевых администраторов безостановочно модернизировать свои проводные сегменты, поддерживающие работу Wi-Fi. На сегодняшний день при использовании высокоскоростных точек доступа проводные интерфейсы коммутаторов доступа начинают становиться узким местом, ограничивая скорости передачи данных в беспроводном сегменте. Это кажется невероятным, но даже гигабитного интерфейса порой уже становится недостаточно. Однако переход к использованию сетей на базе 10GE не будет считаться оправданным в течение ещё долгого времени, так как пока скорости, предоставляемые Wi-Fi точками доступа, не планируют перешагнуть этот рубеж.
Предвидя осложнение ситуации в проводном сегменте в связи с появлением устройств с поддержкой 802.11AC Wave 2, компания Cisco Systems совместно с рядом других производителей основала в 2014 году альянс NBASE-T. Целью данной организации стала разработка стандартов Ethernet, позволяющих осуществлять передачу данных на скоростях 2,5 и 5 Гбит/с, используя существующую кабельную инфраструктуру категорий 5е и 6.
Чем же грозит сетевым администраторам появление устройств с поддержкой «второй волны» стандарта 802.11AC? Во-первых, произойдёт увеличение максимальных теоретических скоростей передачи данных до 6.8 Гбит/с. Конечно, это лишь теоретический максимум (реальные скорости окажутся традиционно в два раза ниже), к тому же достижимый лишь при использовании самых производительных клиентов, расположенных в непосредственной близости от точки доступа. Второе улучшение, предусмотренное в стандарте 802.11AC Wave 2, состоит в поддержке технологии MU-MIMO. Использование MU-MIMO позволит более эффективно распределять доступную полосу пропускания между несколькими беспроводными клиентами, работающими одновременно. Так, например, точка доступа с антенной конфигурацией 4x4 сможет обслуживать двух клиентов 2x2 одновременно, а не последовательно, как это было раньше.
Оба улучшения, доступные в 802.11AC Wave 2, приведут к значительно большей утилизации проводных сегментов сети. Именно для устранения узких мест в современных L2-сегментах и были разработаны стандарты NBASE-T, позволяющие с минимальными затратами подготовиться к внедрению беспроводного оборудования с поддержкой IEEE 802.11AC Wave 2. Кроме этого, в NBASE-T нельзя не отметить наличие поддержки технологии Power over Ethernet, позволяющей осуществлять удалённое питание точек доступа, камер видеонаблюдения и иного сетевого оборудования.
Сегодня в нашей тестовой лаборатории находится коммутатор Cisco Catalyst WS-C3560CX-8XPD-S (IOS версии 15.2(6)E), обладающий двумя мультигигабитными интерфейсами. Указанные интерфейсы поддерживают следующие скорости передачи: 100 Мбит/с, 1 Гбит/с, 2.5 Гбит/с, 5Гбит/с и 10 Гбит/с. Конечно же, два мультигигабитных порта – не единственные интерфейсы коммутатора. Модель 3560CX-8XPD оснащена также шестью портами Gigabit Ethernet, а также двумя разъёмами для модулей SFP+. Все восемь медных интерфейсов поддерживают передачу питания PoE+, энергетический бюджет коммутатора составляет 240 Вт.
Конфигурация
Коммутатор Cisco 3560CX-8XPD несёт на борту четыре интерфейса 10GE: Te1/0/1, Te1/0/2, Te1/0/7 и Te1/0/8, два последних как раз и обладают поддержкой NBASE-T.
fox_3560CX-8XPD#sho int status
Port Name Status Vlan Duplex Speed Type
Gi1/0/1 notconnect 1 auto auto 10/100/1000BaseTX
Gi1/0/2 notconnect 1 auto auto 10/100/1000BaseTX
Gi1/0/3 notconnect 1 auto auto 10/100/1000BaseTX
Gi1/0/4 notconnect 1 auto auto 10/100/1000BaseTX
Gi1/0/5 notconnect 1 auto auto 10/100/1000BaseTX
Gi1/0/6 notconnect 1 auto auto 10/100/1000BaseTX
Te1/0/7 connected 1 a-full 100 100/1G/2.5G/5G/10GBaseT
Te1/0/8 connected 1 a-full 100 100/1G/2.5G/5G/10GBaseT
Te1/0/1 notconnect 1 full 10G Not Present
Te1/0/2 notconnect 1 full 10G Not Present
Мультигигабитные интерфейсы не требуют какой-либо дополнительной конфигурации – даже скорость может быть определена автоматически.
fox_3560CX-8XPD(config)#int te1/0/7
fox_3560CX-8XPD(config-if)#?
Interface configuration commands:
aaa Authentication, Authorization and Accounting.
access-session Access Session specific Interface Configuration Commands
arp Set arp type (arpa, probe, snap) or timeout or log options
auto Configure Automation
auto Configure Automation
bandwidth Set bandwidth informational parameter
bfd BFD interface configuration commands
bgp-policy Apply policy propagated by bgp community string
carrier-delay Specify delay for interface transitions
cdp CDP interface subcommands
channel-group Etherchannel/port bundling configuration
channel-protocol Select the channel protocol (LACP, PAgP)
crypto Encryption/Decryption commands
cts Configure Cisco Trusted Security
dampening Enable event dampening
datalink Interface Datalink commands
default Set a command to its defaults
delay Specify interface throughput delay
description Interface specific description
downshift link downshift feature
exit Exit from interface configuration mode
flow-sampler Attach flow sampler to the interface
flowcontrol Configure flow operation.
help Description of the interactive help system
history Interface history histograms - 60 second, 60 minute and 72 hour
hold-queue Set hold queue depth
ip Interface Internet Protocol config commands
ipv6 IPv6 interface subcommands
isis IS-IS commands
iso-igrp ISO-IGRP interface subcommands
keepalive Enable keepalive
l2protocol-tunnel Tunnel Layer2 protocols
lacp LACP interface subcommands
link Interface link related commands
lldp LLDP interface subcommands
load-interval Specify interval for load calculation for an interface
location Interface location information
logging Configure logging for interface
mac MAC interface commands
macro Command macro
macsec Enable macsec on the interface
mdix Set Media Dependent Interface with Crossover
media-proxy Enable media proxy services
metadata Metadata Application
mka MACsec Key Agreement (MKA) interface configuration
mls mls interface commands
mvr MVR per port configuration
neighbor interface neighbor configuration mode commands
network-policy Network Policy
nmsp NMSP interface configuration
no Negate a command or set its defaults
onep Configure onep settings
ospfv3 OSPFv3 interface commands
pagp PAgP interface subcommands
power Power configuration
priority-queue Priority Queue
queue-set Choose a queue set for this queue
rep Resilient Ethernet Protocol characteristics
rmon Configure Remote Monitoring on an interface
routing Per-interface routing configuration
service-policy Configure CPL Service Policy
shutdown Shutdown the selected interface
small-frame Set rate limit parameters for small frame
snmp Modify SNMP interface parameters
source Get config from another source
spanning-tree Spanning Tree Subsystem
speed Configure speed operation.
srr-queue Configure shaped round-robin transmit queues
storm-control storm configuration
subscriber Subscriber inactivity timeout value.
switchport Set switching mode characteristics
timeout Define timeout values for this interface
topology Configure routing topology on the interface
transmit-interface Assign a transmit interface to a receive-only interface
tx-ring-limit Configure PA level transmit ring limit
udld Configure UDLD enabled or disabled and ignore global UDLD setting
vtp Enable VTP on this interface
fox_3560CX-8XPD(config-if)#speed ?
100 Force 100 Mbps operation
1000 Force 1000 Mbps operation
10000 Force 10000 Mbps operation
2500 Force 2500 Mbps operation
5000 Force 5000 Mbps operation
auto Enable AUTO speed configuration
Настройка дуплекса для портов NBASE-T отсутствует.
fox_3560CX-8XPD(config)#int gi1/0/1
fox_3560CX-8XPD(config-if)#du ?
auto Enable AUTO duplex configuration
full Force full duplex operation
half Force half-duplex operation
fox_3560CX-8XPD(config-if)#int te1/0/7
fox_3560CX-8XPD(config-if)#du ?
% Unrecognized command
Что же касается работы функции Auto MDI/MDIX, то в данном коммутаторе определение использованного кабеля производится вне зависимости от скорости, на которой функционирует интерфейс.
При использовании автоматического согласования скорости администратор может в явном виде указать, какие скорости допустимы для согласования. Справедливости ради, стоит отметить, что аналогичная настройка доступна и для гигабитных интерфейсов тоже.
fox_3560CX-8XPD(config-if)#spe au ?
100 Include 100 Mbps in auto-negotiation advertisement
1000 Include 1000 Mbps in auto-negotiation advertisement
10000 Include 10000 Mbps in auto-negotiation advertisement
2500 Include 2500 Mbps in auto-negotiation advertisement
5000 Include 5000 Mbps in auto-negotiation advertisement
Мы соединили патч-кордом интерфейсы Te1/0/7 и Te1/0/8 между собой. Вывод некоторых диагностических команд представлен ниже.
fox_3560CX-8XPD#sho run int te1/0/7
Building configuration...
Current configuration : 59 bytes
!
interface TenGigabitEthernet1/0/7
load-interval 30
end
fox_3560CX-8XPD#sho run int te1/0/8
Building configuration...
Current configuration : 71 bytes
!
interface TenGigabitEthernet1/0/8
load-interval 30
speed 5000
end
fox_3560CX-8XPD#sho int status
Port Name Status Vlan Duplex Speed Type
Gi1/0/1 notconnect 1 auto auto 10/100/1000BaseTX
Gi1/0/2 notconnect 1 auto auto 10/100/1000BaseTX
Gi1/0/3 notconnect 1 auto auto 10/100/1000BaseTX
Gi1/0/4 notconnect 1 auto auto 10/100/1000BaseTX
Gi1/0/5 notconnect 1 auto auto 10/100/1000BaseTX
Gi1/0/6 notconnect 1 auto auto 10/100/1000BaseTX
Te1/0/7 connected 1 a-full a-5000 100/1G/2.5G/5G/10GBaseT
Te1/0/8 connected 1 a-full 5000 100/1G/2.5G/5G/10GBaseT
Te1/0/1 notconnect 1 full 10G Not Present
Te1/0/2 notconnect 1 full 10G Not Present
fox_3560CX-8XPD#sho int te1/0/7
TenGigabitEthernet1/0/7 is up, line protocol is up (connected)
Hardware is Ten Gigabit Ethernet, address is 9c57.adb0.3487 (bia 9c57.adb0.3487)
MTU 1500 bytes, BW 5000000 Kbit/sec, DLY 10 usec,
reliability 255/255, txload 1/255, rxload 1/255
Encapsulation ARPA, loopback not set
Keepalive set (10 sec)
Full-duplex, 5000Mb/s, media type is 100/1G/2.5G/5G/10GBaseT
input flow-control is off, output flow-control is unsupported
ARP type: ARPA, ARP Timeout 04:00:00
Last input 00:00:01, output 00:00:01, output hang never
Last clearing of "show interface" counters never
Input queue: 0/75/0/0 (size/max/drops/flushes); Total output drops: 0
Queueing strategy: fifo
Output queue: 0/40 (size/max)
30 second input rate 0 bits/sec, 0 packets/sec
30 second output rate 1000 bits/sec, 1 packets/sec
538 packets input, 102715 bytes, 0 no buffer
Received 325 broadcasts (325 multicasts)
0 runts, 0 giants, 0 throttles
0 input errors, 0 CRC, 0 frame, 0 overrun, 0 ignored
0 watchdog, 325 multicast, 0 pause input
0 input packets with dribble condition detected
1622 packets output, 172091 bytes, 0 underruns
0 output errors, 0 collisions, 1 interface resets
0 unknown protocol drops
0 babbles, 0 late collision, 0 deferred
0 lost carrier, 0 no carrier, 0 pause output
0 output buffer failures, 0 output buffers swapped out
fox_3560CX-8XPD#sho int te1/0/8
TenGigabitEthernet1/0/8 is up, line protocol is up (connected)
Hardware is Ten Gigabit Ethernet, address is 9c57.adb0.3488 (bia 9c57.adb0.3488)
MTU 1500 bytes, BW 5000000 Kbit/sec, DLY 10 usec,
reliability 255/255, txload 1/255, rxload 1/255
Encapsulation ARPA, loopback not set
Keepalive set (10 sec)
Full-duplex, 5000Mb/s, media type is 100/1G/2.5G/5G/10GBaseT
input flow-control is off, output flow-control is unsupported
ARP type: ARPA, ARP Timeout 04:00:00
Last input 00:00:01, output 00:00:09, output hang never
Last clearing of "show interface" counters never
Input queue: 0/75/0/0 (size/max/drops/flushes); Total output drops: 0
Queueing strategy: fifo
Output queue: 0/40 (size/max)
30 second input rate 0 bits/sec, 0 packets/sec
30 second output rate 0 bits/sec, 0 packets/sec
1626 packets input, 172811 bytes, 0 no buffer
Received 1413 broadcasts (1397 multicasts)
0 runts, 0 giants, 0 throttles
4 input errors, 0 CRC, 0 frame, 0 overrun, 0 ignored
0 watchdog, 1397 multicast, 0 pause input
0 input packets with dribble condition detected
561 packets output, 104187 bytes, 0 underruns
0 output errors, 0 collisions, 1 interface resets
0 unknown protocol drops
0 babbles, 0 late collision, 0 deferred
0 lost carrier, 0 no carrier, 0 pause output
0 output buffer failures, 0 output buffers swapped out
fox_3560CX-8XPD#
Перед тем как непосредственно перейти к нагрузочному тестированию, мы решили подключить точку доступа с поддержкой PoE к интерфейсу Te1/0/7 и предоставить нашим читателям некоторую диагностическую информацию.
fox_3560CX-8XPD#sho power inline tenGigabitEthernet 1/0/7
Interface Admin Oper Power Device Class Max
(Watts)
--------- ------ ---------- ------- ------------------- ----- ----
Te1/0/7 auto on 15.4 Ieee PD 4 30.0
Interface AdminPowerMax AdminConsumption
(Watts) (Watts)
---------- --------------- --------------------
Te1/0/7 30.0 15.4
fox_3560CX-8XPD#sho lldp ne de
fox_3560CX-8XPD#sho lldp ne detail
------------------------------------------------
Local Intf: Te1/0/7
Chassis id: b8ec.a3ac.5c19
Port id: 1
Port Description: UPLINK
System Name: WAC6103D-I
System Description:
Linux
Time remaining: 118 seconds
System Capabilities: B,W,R
Enabled Capabilities: B,W,R
Management Addresses:
IP: 192.168.1.2
Auto Negotiation - not supported
Physical media capabilities - not advertised
Media Attachment Unit type - not advertised
Vlan ID: - not advertised
Total entries displayed: 1
fox_3560CX-8XPD(config)#int te1/0/7
fox_3560CX-8XPD(config-if)#po
fox_3560CX-8XPD(config-if)#power ?
inline Inline power configuration
fox_3560CX-8XPD(config-if)#power i
fox_3560CX-8XPD(config-if)#power inline ?
auto Automatically detect and power inline devices
consumption Configure the inline device consumption
never Never apply inline power
police Police the power drawn on the port
port Configure Port Power Level
static High priority inline power interface
На этом раздел, посвящённый конфигурированию мультигигабитных интерфейсов, подошёл к концу.
Тестирование
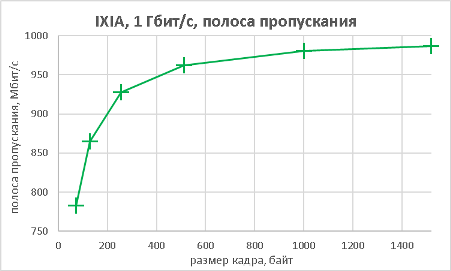
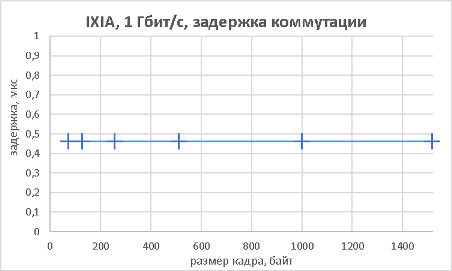
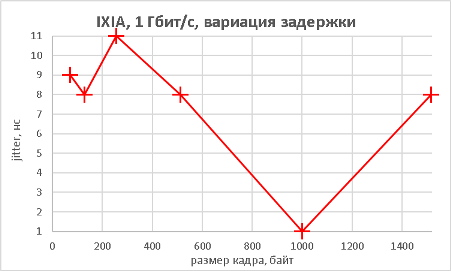
В данном разделе мы хотим предоставить нашим читателям результаты тестов производительности коммутатора не только при использовании мультигигабитных интерфейсов, но и «стандартных» портов. В качестве трафик-генератора использовался программно-аппаратный комплекс IXIA. Начать мы решили с измерения производительности (полоса пропускания, задержка и джиттер) модели 3560CX-8XPD, выполняющей коммутацию с использованием интерфейсов Gigabit Ethernet. Измерения производились для фреймов различной длины. Во время проведения данных тестов мы не фиксировали потери пакетов (исключая тест маршрутизации IPv6), поэтому данный график мы решили не включать в статью.
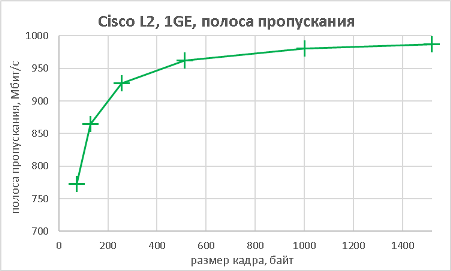
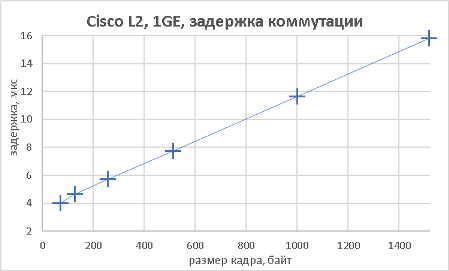
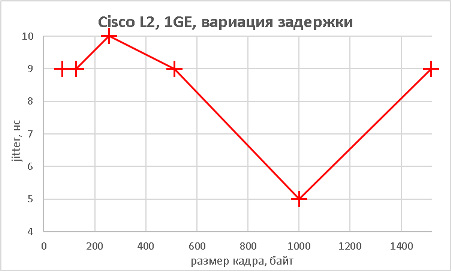
Поскольку модель Cisco Catalyst 3560CX-8XPD обладает возможностью выполнять не только коммутацию Ethernet-кадров, но маршрутизацию IP-пакетов, мы решили не оставлять данную функциональность без внимания.
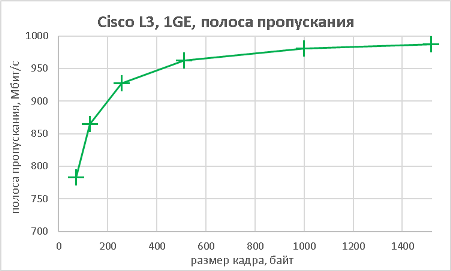
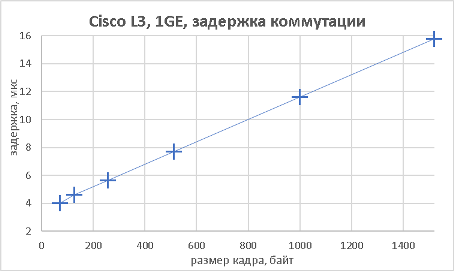
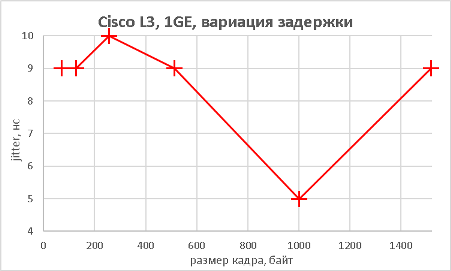
Как видно из приведённых выше графиков, производительность устройства практически не отличается как при выполнении функций L2, так и L3.
Следующим этапом стало измерение производительности коммутатора при подключении к его оптическим портам 10GE также в L2 и L3 режимах.
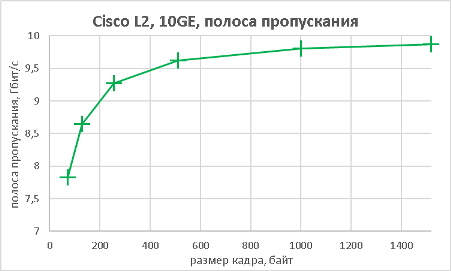
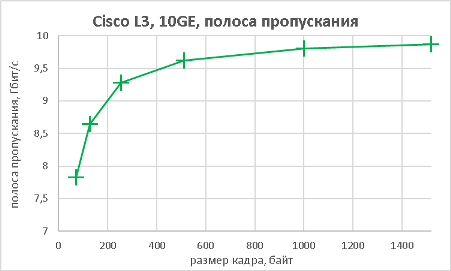
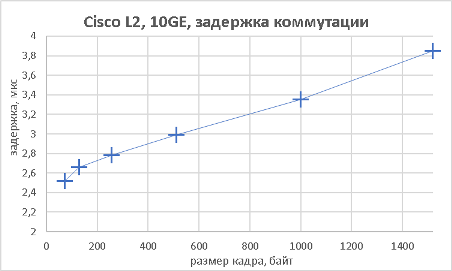
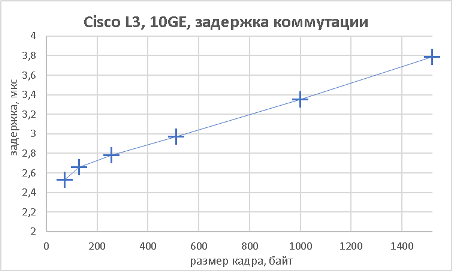
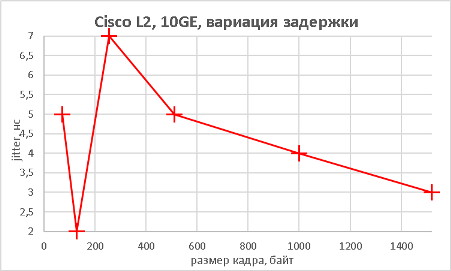
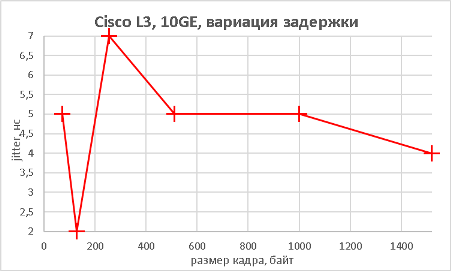
Тестируемый коммутатор может выполнять не только маршрутизацию трафика IPv4, но также и IPv6. Естественно, мы не оставили без внимания такую возможность.
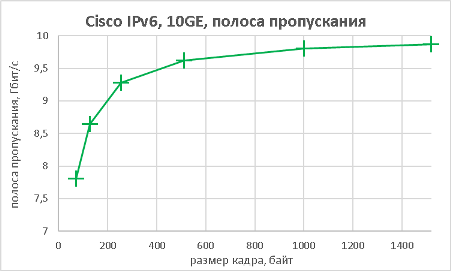

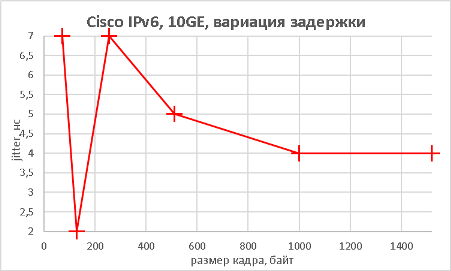
Здесь стоит отметить, что при маршрутизации пакетов, размер которых составлял 72 байта, наблюдались потери пакетов 0.029%. Величина потерь невелика, однако мы всё равно посчитали необходимым упомянуть об этом.
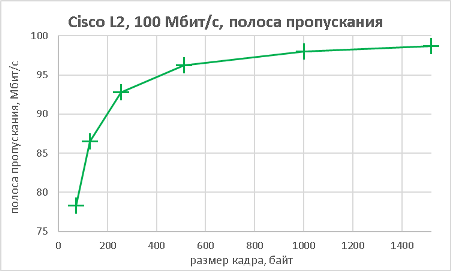
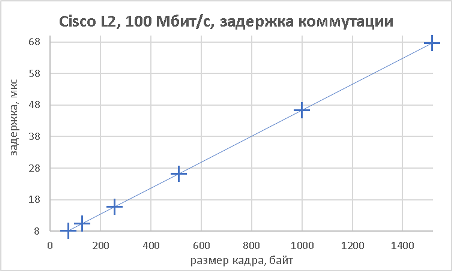
Мы подошли, пожалуй, к самой интересной части данного раздела – измерению производительности коммутатора при использовании портов NBASE-T. Трафик-генератор подключался к оптическим интерфейсам коммутатора (10GE). Мультигигабитные интерфейсы были соединены друг с другом с помощью патч-корда длиной 0.5 метра. На графиках ниже представлены значения скорости, задержки и джиттера для всех поддерживаемых интерфейсами скоростей. При построении графиков зависимости задержки от размера пакетов мы, естественно, учитывали, что в данной схеме фреймы проходят коммутатор дважды.
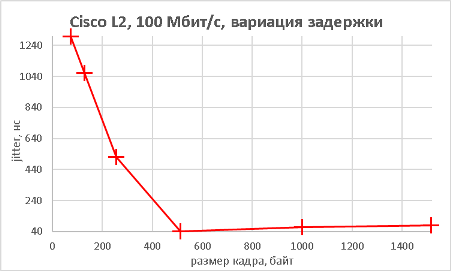
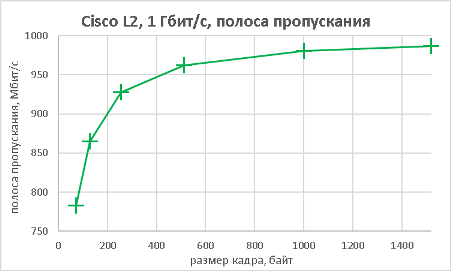
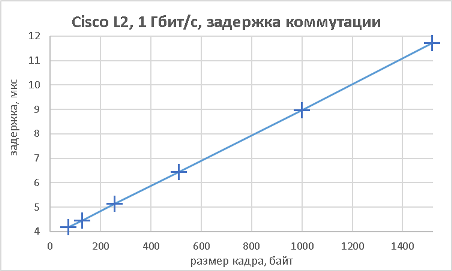
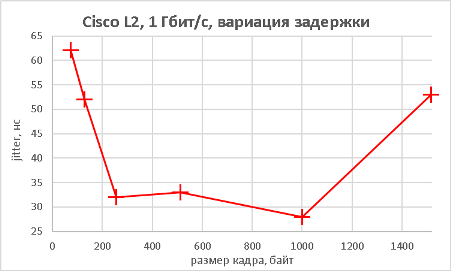
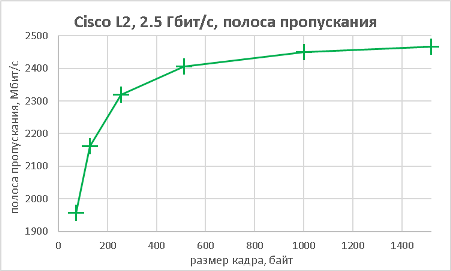
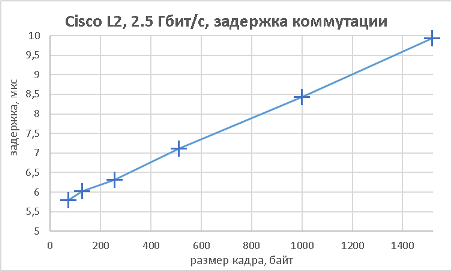
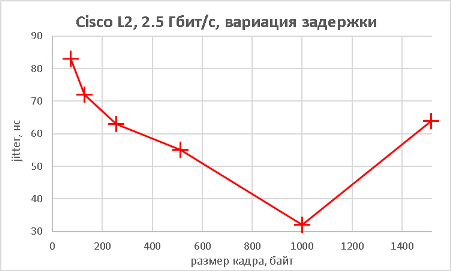
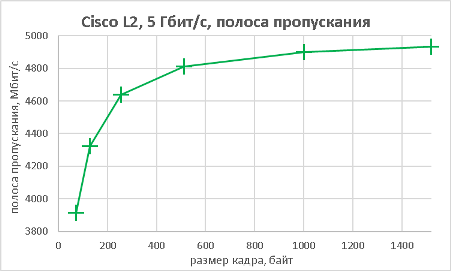
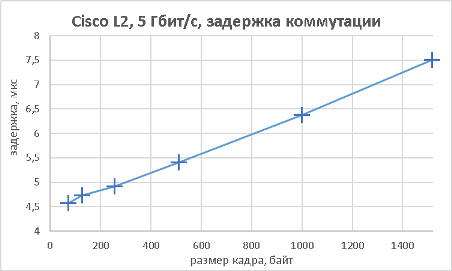
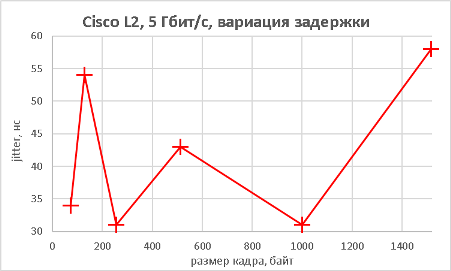
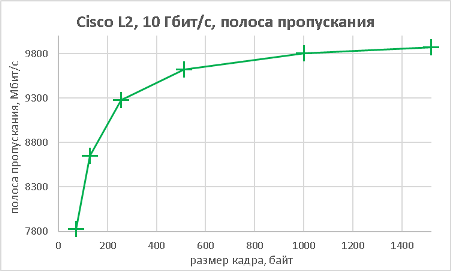
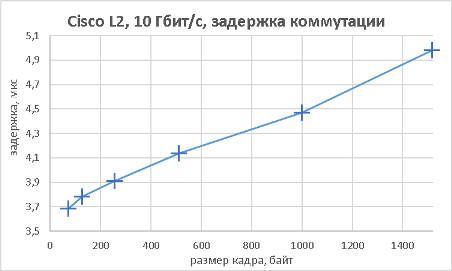
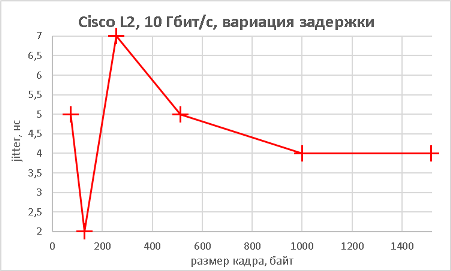
В заключение данного раздела нам бы хотелось предоставить нашим читателям те же зависимости, но без использования коммутатора, то есть в ситуации, когда порты трафик-генератора соединялись друг с другом напрямую.
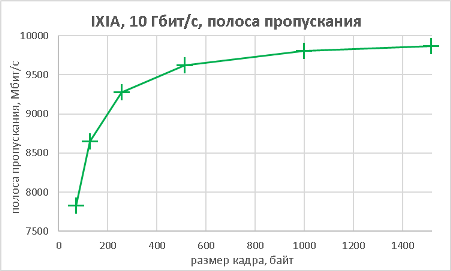
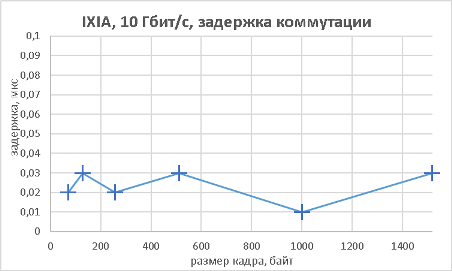
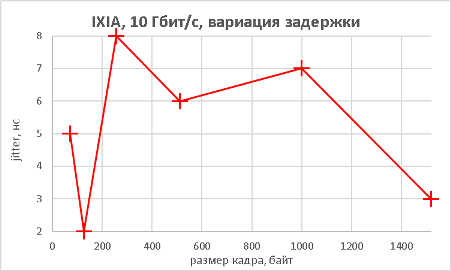
На этом мы завершаем раздел тестирования и переходим к подведению итогов.
Заключение
В данной статье мы рассмотрели медные мультигигабитные интерфейсы на примере компактного коммутатора Cisco Catalyst 3560CX-8XPD, обладающего двумя портами с поддержкой NBASE-T. Использование портов NBASE-T позволит с минимальными затратами обновить существующие проводные сегменты сети и подготовиться к развёртыванию беспроводных сетей следующего поколения IEEE 802.11AC Wave 2. Использование NBASE-T позволяет значительно увеличить производительность проводных сегментов без замены кабельной инфраструктуры. Поддержка мультигигабитными интерфейсами также и «стандартных» скоростей 1GE и 10GE позволит осуществить замену оборудования максимально плавно и последовательно.
Стоит также заметить, что появление новых стандартов с «промежуточными» скоростями произошло не только в мире медных сетевых интерфейсов с разъёмами RJ45 (8P8C), но также и в сегменте оптических сетей. Примером может служить коммутатор Cisco Nexus 3232C с высокой плотностью портов, несущий на борту 32 фиксированных 100GE интерфейса формата QSFP28, что позволяет обеспечить поддержку следующих скоростей оптических интерфейсов: 10G/25G/40G/50G/100G. Однако это уже совсем другая история.
Обзор
Power over IP (PoIP) – технология, позволяющая передавать удалённому устройству электрическую энергию вместе с данными по одному кабелю витой пары. Данная технология предназначена для разнообразных датчиков, сенсоров, интеллектуальных реле, передатчиков ZigBee и других беспроводных технологий со сверхнизким энергопотреблением, к которым по той или иной причине нежелательно или невозможно проводить отдельный электрический кабель. Предполагается, что технология Power over IP будет наиболее востребованной для построения распределённых сенсорных сетей, а также для поддержки IoT (Internet of Things – Интернет Вещей).
Технология PoIP на данный момент находится в стадии разработки, происходит подготовка к публикации первой версии черновика стандарта, однако ряд компаний уже готовятся к пилотному использованию разрабатываемой технологии в своём оборудовании. К числу вендоров, принимающих активное участие в разработке прототипов устройств с поддержкой PoIP, относятся: ARM, Cisco, Intel, ASUS, Broadcom, Realtek и STMicroelectronics.
Оборудование и принцип работы
Технология PoIP не оказывает влияния на качество передаваемых данных. Передача энергии производится с помощью свойств физического уровня Ethernet. Основное отличие PoIP от PoE (Power over Ethernet) состоит в том, что PoE использует так называемую внеполосную передачу энергии, тогда как питание PoIP устройств производится с помощью энергии, передаваемой самим сигналом.
Для своей работы технология PoIP требует от коммутационного оборудования поддержки Ethernet стандарта 10Base-T (IEEE 802.3) в полнодуплексном режиме. Стоит отметить, что рекомендованной настройкой со стороны коммутатора является автоматическое определение скорости и дуплекса, хотя не запрещается и ручное конфигурирование. Всё оборудование с поддержкой PoIP должно также поддерживать и автоматическое определение разводки кабеля (Auto MDI/MDIX). Стандарт 10Base-T определяет для передающей пары значение напряжения ±2.5 В, что вместе с максимальным током, равным 250мА, позволяет поддерживать работу устройства мощностью до 0,5 Ватт. Стандарт 10Base-T Ethernet поддерживает кабельные сегменты длиной до 100 метров, однако при использовании PoIP стоит учитывать, что при передаче энергии через витую пару происходит существенная потеря мощности в зависимости от расстояния и толщины проводника, поэтому при подключении PoIP устройств рекомендуется использовать максимально короткие и толстые кабели. Обычно толщина проводника для витой пары указывается в AWG (American Wire Gauge (Американский Калибр Проводников)). В таблице ниже представлено соответствие толщины кабеля в AWG площади сечения проводника для одножильных и многожильных кабелей.
| AWG | Площадь поперечного сечения, мм2 | |
| Одножильный кабель | Многожильный кабель | |
| 22 | 0,325 | 0,327-0,352 |
| 24 | 0,205 | 0,201-0,226 |
| 26 | 0,128 | 0,14-0,153 |
Удельное сопротивление меди примерно равно 17мОм*мм2/м, то есть одножильная витая пара 24 AWG длиной 100 метров будет иметь сопротивление более 16,5 Ом. Таким образом, максимальная мощность, на которую может «рассчитывать» PoIP устройство в данном случае, не будет превышать 0,2 Ватт.
В случае перегруженной сети использование UDP не выглядит целесообразным из-за того, что UDP не гарантирует доставку данных. В такой ситуации необходимо использовать unicast и TCP как надёжный транспортный протокол. Чтобы ещё более увеличить эффективность PoIP необходимо перейти к использованию jumbo кадров, так как никакие транспортные заголовки не используются в PoIP для передачи энергии.
До настоящего момента мы говорили только о «клиентской» части технологии PoIP. Однако сам по себе коммутатор не будет снабжать подключённые к нему устройства энергией даже мощностью 0.5 Ватт. Для того чтобы осуществлялась передача энергии, необходим поток специально сформированного трафика. Генерировать и передавать такой трафик может любое устройство с поддержкой IPv4. Из соображений безопасности, а также с целью уменьшения нагрузки на сетевую инфраструктуру, генерирующее трафик оборудование должно размещаться в одном локальном сегменте с PoIP клиентами. Уменьшение нагрузки на сеть происходит также за счёт использования групповых рассылок (multicast). При каждом запуске и во время работы в автоматическом режиме производится выбор наиболее оптимального профиля трафика (паттерна), позволяющего максимизировать получаемую клиентами энергию. Если по какой-либо причине оптимальный профиль трафика для одного из устройств отличается от согласованного для остальных устройств в данной сети, то для такого клиента допускается генерирование индивидуального потока (unicast).
Отказоустойчивость
Все PoIP клиенты должны регистрироваться на всех локальных генераторах и сообщать им об оптимальных паттернах трафика. Однако в каждый момент времени отправку трафика производит только один генератор. Все остальные генерирующие устройства также подписываются на получение потока от активного источника. Групповой поток трафика от активного источника выполняет также функции keepalive сообщений. При отсутствии потока трафика в течение 50 мс роль активного устройства принимает на себя оборудование с наивысшим значением приоритета. Приоритет может принимать значения от 1 до 255, по умолчанию 100.
Клиентское PoIP устройство должно обладать встроенной аккумуляторной батареей и быть способно пережить кратковременное пропадание потока IP-трафика.
Вендоры
На момент публикации о разработке модуля, генерирующего IP-трафик, сообщили три компании: ASUS, Cisco и Intel.
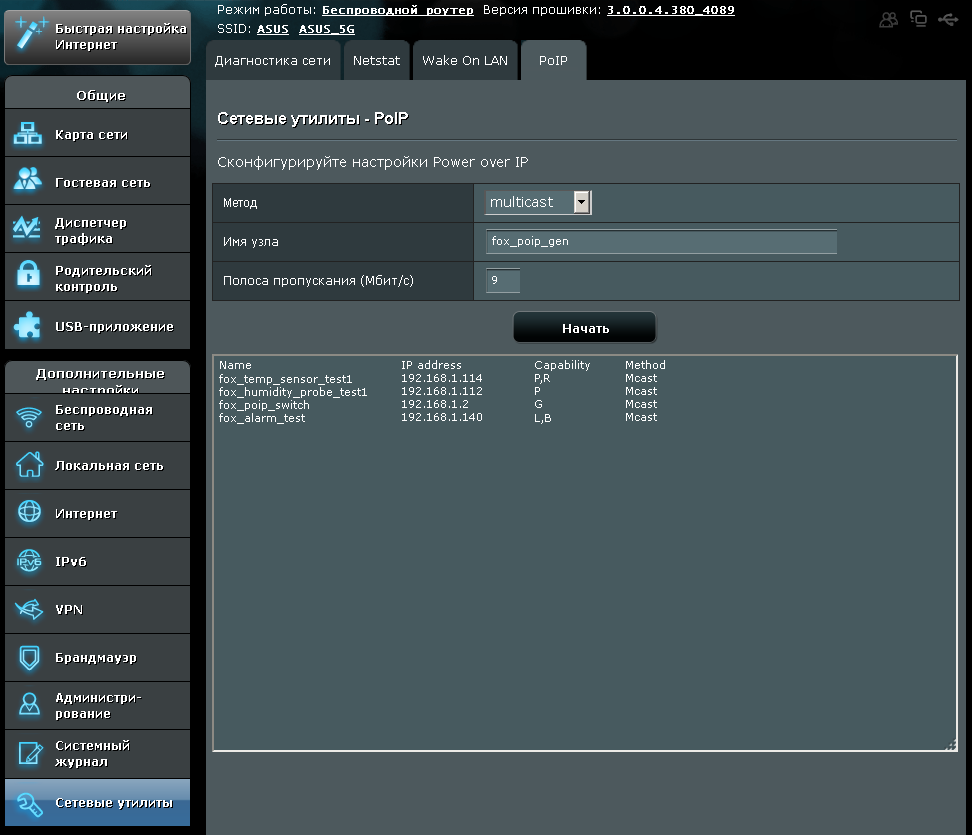
Компания ASUS начала встраивать генератор трафика в топовые модели своих маршрутизаторов. Управление производится с помощью скрытой вкладки «PoIP gen» пункта меню «Сетевые утилиты».
Все промышленные маршрутизаторы, а также L3-коммутаторы компании Cisco Systems, работающие под управлением операционных систем IOS (начиная с версии 15.6(2)T), IOS XE (с версии 16.04.01 Everest) и IOS XR (с версии 6.1.3), обладают набором скрытых команд, позволяющих включить встроенный в систему генератор. Поддержка технологии PoIP линейкой устройств на базе NX-OS не планируется.
cisco#sho poip ?
% Unrecognized command
cisco#sho poip devices
Capability codes:
(G) Generator, (P) Probe, (L) LED, (W) WLAN Access Point
(R) Relay, (S) Station, (B) Beeper, (O) Other
Device ID Hold-time Capability Port ID IP Address
fox_temp_sensor_test1 50 P,R Gi1/0/10 192.168.1.114
fox_humidity_probe_test1 50 P Gi1/0/12 192.168.1.112
fox_alarm_test 50 L,B Gi1/0/24 192.168.1.140
fox_poip_gen 50 G,S Te1/0/4 192.168.1.1
Total entries displayed: 4
cisco#conf t
Enter configuration commands, one per line. End with CNTL/Z.
cisco(config)#poip ?
% Unrecognized command
cisco(config)#poip test
cisco(config-poip)#?
Configure commands:
access-class Filter client devices based on an IP access list
authentication Auth Manager PoIP Configuration Commands
bandwidth Set max bandwidth to utilize
default Set a command to its defaults
description PoIP instance specific description
interface Select an interface to support
logging Handles logging operations
mode PoIP operating mode
network-policy Network Policy
password Secret key for MD5 authentication
pattern Configure a packet pattern
preempt Overthrow lower priority Active generators
priority Priority level
shutdown Shutdown this instance of PoIP
static Define a static PoIP client
timer Hold timer
track Priority tracking
version PoIP version
Утилита компании Intel – Intel PoIP Gen, по заявлению производителя, полностью соответствует RFC3251 (Electricity over IP) и на данный момент проходит стадию внутреннего тестирования, оставаясь недоступной рядовым пользователям.
Развитие стандарта
На данный момент в качестве физической среды используется витая пара Ethernet. В проекте заложена также поддержка оптоволоконного и беспроводного подключений, если удастся ещё больше снизить энергопотребление устройств.
Черновик стандарта предполагает возможность подключения PoIP устройства с помощью двух кабелей витая пара для удвоения энергетического бюджета.
Также среди нововведений заявлена поддержка следующей версии протокола IP – IPv6.
Появление в ближайшем будущем более энергоэффективных клиентских устройств на базе SoC чипов с пониженным энергопотреблением позволит значительно расширить область применения технологии Power over IP.
DHCP в деталях
Назначение протокола и основные принципы его работы
Дополнительные возможности: relay
Дополнительные возможности: option 82, snooping
Дополнительные возможности: импорт параметров
Дополнительные возможности: поддержка VRF
Дополнительные возможности: Voice VLAN
Введение
За кажущейся простотой протокола DHCP скрывается большой набор возможностей, о которых администраторы часто не подозревают. В данной статье мы не станем подробно изучать все возможности протокола, однако в некоторые интересные детали всё-таки погрузимся. Мы не претендуем на максимально полное рассмотрение теоретических аспектов, за которыми читатель может обратиться к любым специализированным изданиям. Здесь же хотелось бы особо подчеркнуть, что, несмотря на то, что рассматривать работу DHCP (RFC2131) в основном мы будем на оборудования компании Cisco, большинство параметров также доступны в коммутаторах и маршрутизаторах других вендоров. Также хотелось бы отметить, что данная статья рассчитана на широкий круг читателей, поэтому начинать мы будем с самых простых, можно даже сказать, элементарных вещей, однако, надеемся, что не отпугнём этим более продвинутого читателя.
Итак, скорее приступим!
Назначение протокола и основные принципы его работы
Протокол DHCP (Dynamic Host Configuration Protocol) предназначен для централизованного управления IP-параметрами конечного клиентского оборудования. Конечно же, никто не запрещает использовать DHCP для настройки серверов или сетевого оборудования, однако чаще всего в таких случаях применяется статическая конфигурация, которая считается более предсказуемой. Мы специально отметили, что протокол используется для управления именно IP-параметрами, потому что у многих администраторов сложился неправильный стереотип, заключающийся в том, что клиент-серверный протокол DHCP ограничен лишь настройкой IP-адреса. IP-адрес – лишь один из параметров, которые могут быть сконфигурированы с помощью обсуждаемого протокола. Какие же ещё параметры могут быть переданы узлу? К их числу (но не ограничиваясь ими) относятся следующие (RFC1533 и RFC2132): маска подсети, шлюз по умолчанию, адреса DNS и WINS серверов, имя домена и самого узла, маршруты на определённые подсети, временную зону и адрес сервера времени, адрес загрузочного образа, TTL и MTU, адреса POP3 и SMTP серверов, время аренды адреса. Не все опции могут использоваться или поддерживаться клиентом или сервером, однако часто клиенты и серверы DHCP всё-таки поддерживают довольно широкий набор опций.
Получение IP-параметров производится с помощью четырёх сообщений, которыми обмениваются клиент и сервер.
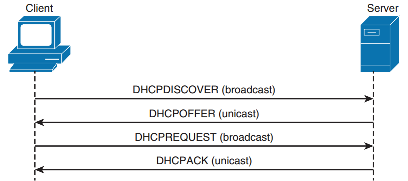
Сообщение DHCP discover отправляется клиентом для обнаружения DHCP-сервера в локальном сегменте сети. Забегая вперёд, отметим, что современные топологии не подразумевают непосредственной установки сервера в каждую виртуальную сеть (VLAN), в которой расположены клиентские узлы. Вместо этого используются особый ретранслятор, о котором мы поговорим чуть позже.
Получив сообщение DHCP discover, сервера DHCP отвечают клиенту сообщением DHCP offer, содержащим предлагаемые параметры. Получив несколько таких предложений, клиент может выбрать из них то, которое его максимально устраивает. Обычно, правда, выбирается первое полученное сообщение DHCP offer. Стоит отметить, что в этот момент сервер лишь на короткое время резервирует за клиентом предложенный IP-адрес, и если клиент не запросит его использование, - освободит для дальнейшего использования (вернёт адрес в пул).
Выбрав одно из предложений, клиент отправляет широковещательный запрос DCHP request серверу на закрепление за ним предложенных параметров. До получения подтверждения от сервера клиент не вправе использовать избранный IP-адрес. Широковещательное сообщение здесь используется в том числе и для того, чтобы уведомить остальные серверы, что их предложения не рассматриваются, что позволит им быстрее вернуть адрес в пул.
Получив сообщение DHCP request, сервер отправляет клиенту сообщение DCHP ack, подтверждающее за клиентом право использования выданного IP-адреса. Стоит заметить, что в некоторых случаях, сервер может не подтвердить клиенту запрос на использование адреса. Такая ситуация может произойти, например, в случае, когда сервер выдал данный IP-адрес другому клиенту, либо была произведена переконфигурация самого DHCP-сервера. Если сервер не может подтвердить клиенту использование ранее предложенных параметров, то сервер отправляет клиенту сообщение DHCP nack.
Одной из обязательных опций, сообщаемых сервером клиенту, является время аренды IP-адреса. Данный параметр указывает на интервал времени, в течение которого клиент в праве использовать полученные IP-параметры. По истечении данного времени, клиент обязан освободить занимаемый IP-адрес, либо произвести его продление. Если клиент собирается освободить занимаемый адрес, то производится отправка сообщения DHCP release. Получив такое сообщение, сервер возвращает IP-адрес, ранее принадлежавший клиенту, в пул свободных адресов.
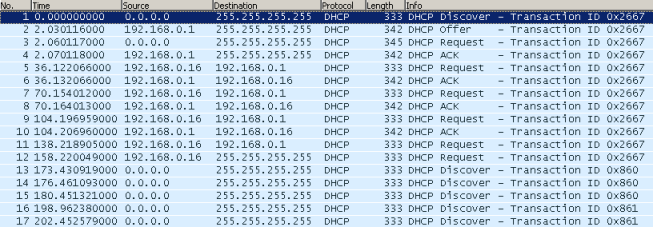
Для наших читателей мы подготовили дамп трафика, содержащий процедуру получения и освобождения IP-адреса хостом. Все файлы дампов, размещённые в данной статье можно открыть с помощью сетевого анализатора Wireshark. Мы настоятельно рекомендуем внимательно изучить все поля во всех пакетах, содержащихся в данном файле. Отфильтровать DHCP-сообщения в большом дампе с помощью Wireshark можно путём использования фильтра «bootp».

Пакеты с первого по четвёртый включительно содержат стандартную процедуру получения IP-параметров. В пакетах 5, 6 и 7 клиентом было отправлено сообщение DHCP release, извещающее сервер о досрочном прекращении аренды.
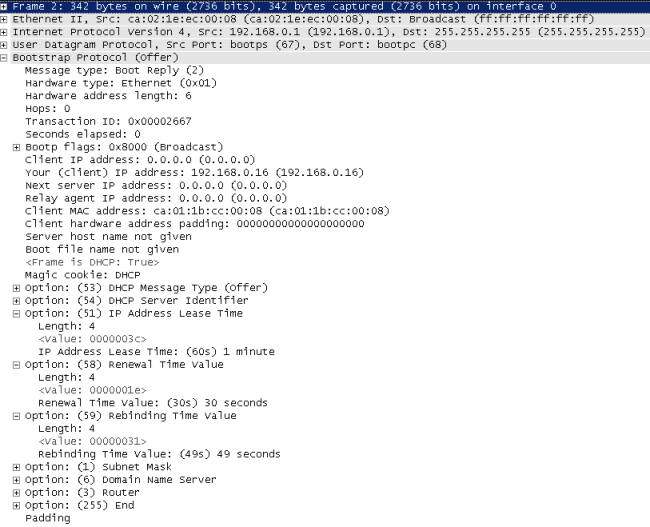
Каким же образом сервер извещает клиента о том, на какое время ему выдаётся IP-адрес? Как и всё в DHCP, данная информация передаётся в пакете в виде опции (опция №51). Кроме этого в протоколе DHCP предусмотрены два таймера, обычно называемые T1 (renewal) и T2 (rebinding), передаваемые опциями 58 и 59, соответственно. Таймер T1 обычно равен половине времени аренды, тогда как T2 соответствует 7/8 времени аренды. Для чего же используются данные таймеры? Спустя время T1 после получения сообщения DHCP ack клиент начинает процедуру обновления IP-параметров (renewing), повторно запрашивая у сервера разрешение на право их использования. Если никаких изменений не произошло, сервер разрешает продление времени аренды путём отправки сообщения DHCP ack. Если же по какой-то причине сервер на запрос о продлении аренды не ответил, спустя время T2 происходит широковещательная отправка сообщения DHCP request, с помощью которого клиент пытается найти сервер, способный продлить аренду полученных ранее IP-параметров. Если же данная попытка не увенчалась успехом, то по окончанию времени аренды клиент обязан освободить полученный IP-адрес.
В предыдущем примере сервер устанавливает время аренды, равное семи дням. Мы уменьшили время аренды до одной минуты и пронаблюдали за процессом обмена DHCP-сообщениями. Из приведённого ниже списка пакетов видно, что примерно каждые 30 секунд клиент отправляет сообщение DHCP request, запрашивая у сервера подтверждение на право использования полученных адресов. В ответ на данное сообщение сервер отправляет пакет DHCP ack. Так, например, пары пакетов 5-6, 7-8 и 9-10 являются успешными попытками продления аренды. Пакет №11 содержит сообщение DHCP request, на которое не приходит подтверждение от сервера. Тогда клиент отправляет широковещательный DHCP request (пакет №12), на который (в нашем примере) также не получает подтверждения. Пакеты №№ 13-17 содержат стандартные сообщения DHCP discover, отправляемые после того, как хост отказался от использованного IP-адреса.
На картинке ниже представлено содержимое пакета DHCP offer, содержащее все три таймера.
Если клиентом является маршрутизатор Cisco, то в логе в момент окончания аренды появляются следующие сообщения.
R1#*Aug 11 21:16:12.743: %DHCP-5-RESTART: Interface GigabitEthernet0/0 is being restarted by DHCP
R1#*Aug 11 21:16:14.815: %LINK-5-CHANGED: Interface GigabitEthernet0/0, changed state to administratively down
R1#*Aug 11 21:16:15.815: %LINEPROTO-5-UPDOWN: Line protocol on Interface GigabitEthernet0/0, changed state to down
R1#*Aug 11 21:16:17.847: %LINK-3-UPDOWN: Interface GigabitEthernet0/0, changed state to up
R1#*Aug 11 21:16:18.847: %LINEPROTO-5-UPDOWN: Line protocol on Interface GigabitEthernet0/0, changed state to up
Также нельзя обойти вниманием самое первое сообщение, отправляемое клиентом, - DHCP discover. Опция №55 (Parameter Request List) содержит список опций, интересующих конечное устройство. На картинке ниже представлен такой список, сгенерированный маршрутизатором Cisco 7206VXR (NPE400) с установленной операционной системой IOS версии 15.2(4)M8 ADVENTERPRISEK9, выполняющий функции DHCP-клиента.
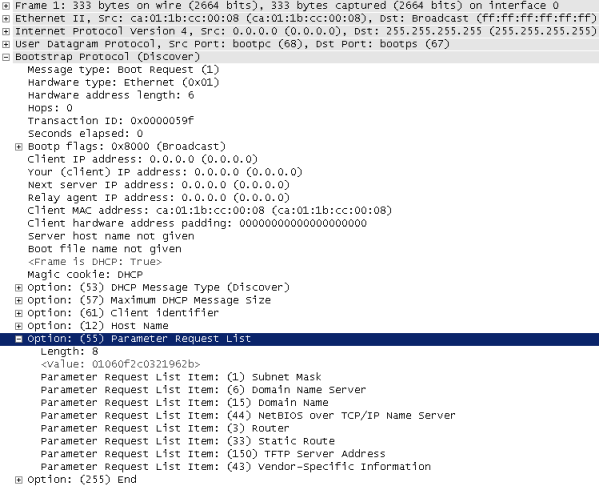
Список запрашиваемых опций не статический, его состав зависит от типа и настройки конечного устройства. Так, например, для клиента на базе операционной системы Windows 7 x64 список несколько отличается и представлен ниже.
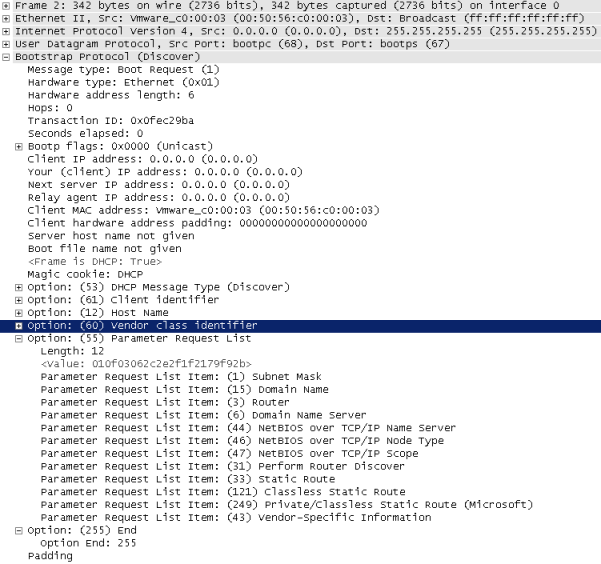
Строго говоря, полностью идентифицировать клиента по списку запрашиваемых параметров нельзя, однако операционная система и используемое программное обеспечение всё же оставляют некоторый отпечаток в DHCP сообщениях, по которому можно приблизительно определить, какой клиент используется. Мы не будем здесь описывать все возможные следы, однако укажем на несколько наиболее интересных. Так, например, маршрутизатор компании Cisco в опцию №61 включит краткую информацию о себе. Опция №12 содержит имя запрашивающего узла. Пожалуй, стоит отметить, что среди возможностей, предоставляемых системой Cisco ISE, присутствует функция определения используемой клиентом операционной системы, но обсуждение вопросов работы данной системы далеко выходит за рамки данной статьи.
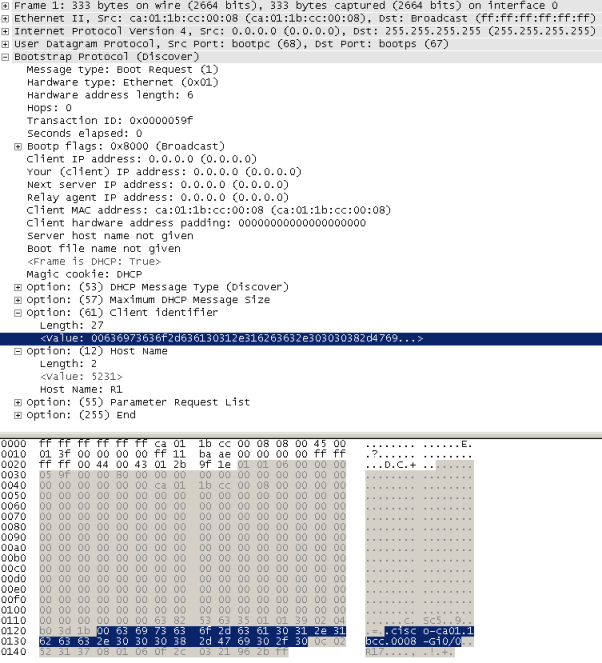
Встроенный в операционную систему Microsoft Windows 7 x64 клиент протокола DHCP с помощью опции №60 (Vendor class identifier) также передаёт о себе некоторые сведения, по которым его можно идентифицировать.
Кроме уже описанных ранее сообщений протокола DHCP существует и ещё одно, которое мы не упомянули, - DHCP information. С его помощью клиент может запросить дополнительную информацию, которую сервер не отправил в сообщении DHCP offer.
На этом мы заканчиваем беглое рассмотрение основных аспектов работы протокола DHCP и переходим к изучению его настройки.
Настройка оборудования
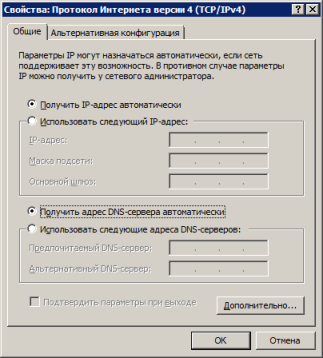
Настроить использование протокола DHCP с клиентской стороны, как правило, труда не составляет. Например, при использовании операционной системы Microsoft Windows 7, единственное, что требуется сделать, - выбрать опцию «Получить IP-адрес автоматически» в настройках протокола IPv4.
Убедиться в успешном получении адреса с помощью GUI тоже не сложно.
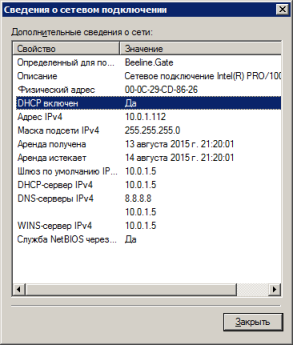
Получить информацию о текущей конфигурации сетевых карт компьютера в современных операционных системах Microsoft Windows можно с помощью команды ipconfig /all.
C:\>ipconfig /all
Настройка протокола IP для Windows
Имя компьютера . . . . . . . . . : torrent
Основной DNS-суффикс . . . . . . :
Тип узла. . . . . . . . . . . . . : Гибридный
IP-маршрутизация включена . . . . : Нет
WINS-прокси включен . . . . . . . : Нет
Порядок просмотра суффиксов DNS . : Beeline.Gate
Ethernet adapter Подключение по локальной сети 2:
DNS-суффикс подключения . . . . . : Beeline.Gate
Описание. . . . . . . . . . . . . : Сетевое подключение Intel(R) PRO/1000 MT
Физический адрес. . . . . . . . . : 00-0C-29-CD-86-26
DHCP включен. . . . . . . . . . . : Да
Автонастройка включена. . . . . . : Да
IPv4-адрес. . . . . . . . . . . . : 10.0.1.112(Основной)
Маска подсети . . . . . . . . . . : 255.255.255.0
Аренда получена. . . . . . . . . . : 13 августа 2015 г. 21:20:01
Срок аренды истекает. . . . . . . . : 14 августа 2015 г. 21:20:01
Основной шлюз. . . . . . . . . : 10.0.1.5
DHCP-сервер. . . . . . . . . . . : 10.0.1.5
DNS-серверы. . . . . . . . . . . : 8.8.8.8
Основной WINS-сервер. . . . . . . : 10.0.1.5
NetBios через TCP/IP. . . . . . . . : Включен
Отказаться от используемого адреса и запросить новый можно с помощью команд ipconfig /release и ipconfig /renew. Стоит также отметить, что в указанном семействе операционных систем, существует достаточно мощная сетевая утилита netsh, с помощью которой можно просматривать и изменять параметры работы сетевых карт. Так, например, получить информацию об используемых IPv4 адресах можно с помощью вызова netsh interface ipv4 show addresses.
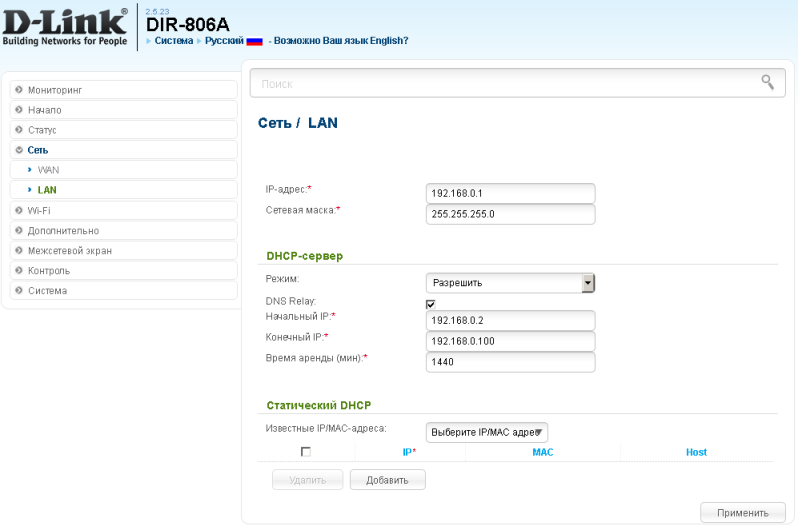
Современные SOHO маршрутизаторы позволяют подключаться к провайдеру, предоставляющему IP-параметры динамически. На картинках ниже показаны типовые настройки подключения к провайдеру на примере двух современных беспроводных маршрутизаторов.
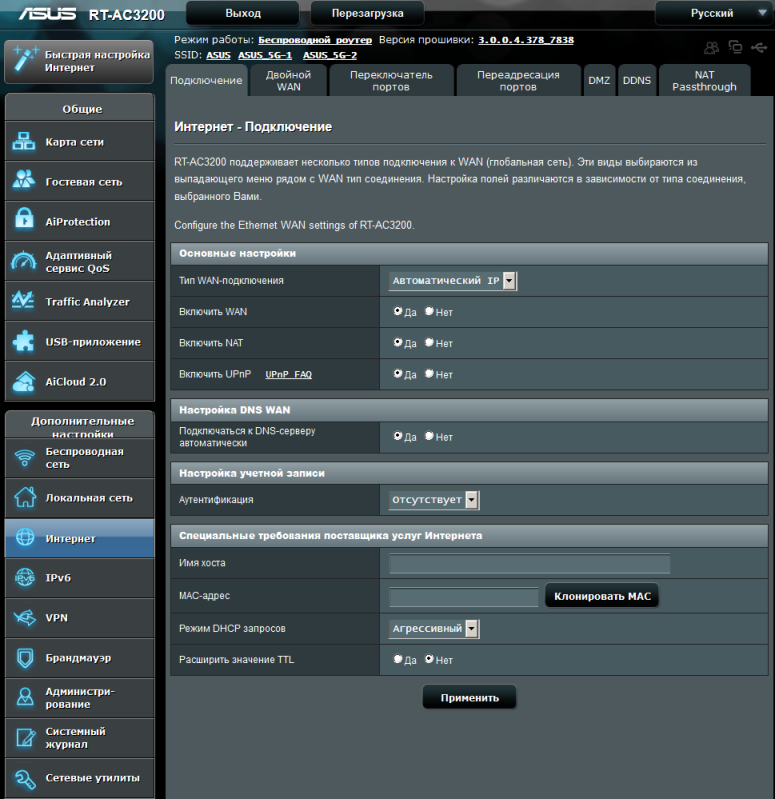
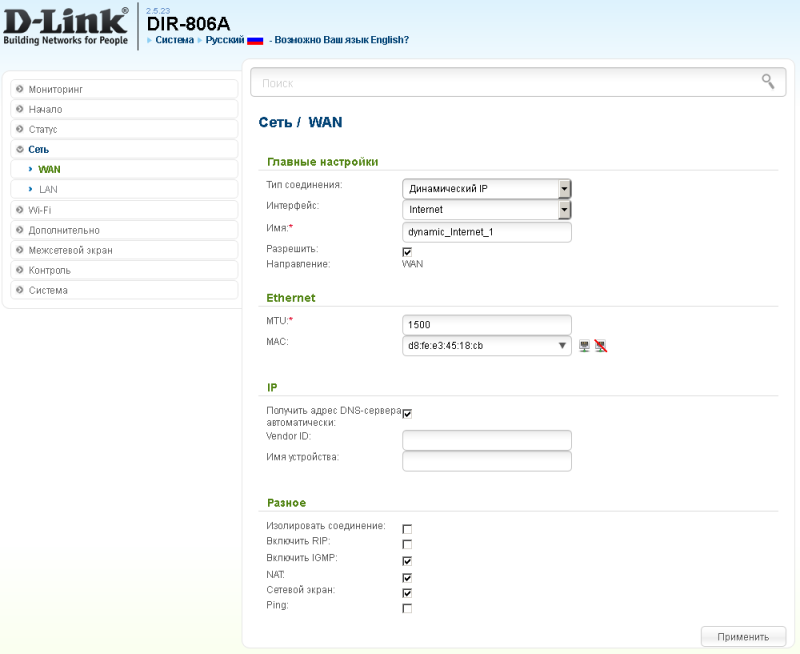
Кроме того, такие устройства обладают также встроенным DHCP-сервером, позволяющим динамически назначать IP-адреса в локальной сети пользователя. Да, параметров здесь не много…
Всю дальнейшую конфигурацию мы будем производить с использованием оборудования Cisco Systems в эмуляторе GNS3 версии 1.3.9. Мы специально решили использовать эмулятор, чтобы наши читатели могли при желании самостоятельно повторить все те настройки, которые будут обсуждаться. Стоит отметить, что в GNS3 версии 1.4.0 появится встроенная поддержка виртуальных машин VMware, что во многом сможет упростить процесс тестирования новых схем сети. Конечно, уже сейчас есть возможность, связать эмулируемое в GNS3 оборудование с реальной сетью и виртуальными сетями VMware с помощью объекта Cloud, однако, особенно удобной такую связку не назовёшь. Однако мы отвлеклись, пора вернуться к DHCP. В качестве маршрутизаторов мы будем использовать модель 7206VXR (NPE400) с IOS ADVENTERPRISEK9 версии 15.2(4)M8. Также нам потребуется L2-коммутатор IOU (встроенный в GNS3 свитч не подойдёт из-за отсутствия нужной функциональности).
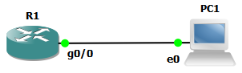
В принципе, в качестве DHCP-клиента в GNS3 можно использовать объект VPCS, допускающий статическое и динамическое назначение IP-параметров. Для демонстрации работы VPCS мы собрали простую схему, приведённую ниже. Настройки серверной стороны – маршрутизатора R1 – мы обсудим позже.
Приведённый ниже листинг отображает процесс динамического получения IP-параметров виртуальным хостом VPCS версии 0.6.1 в эмуляторе GNS3.
PC1> ip ?
ip ARG ... [OPTION]
Configure the current VPC's IP settings
ARG ...:
address [mask] [gateway]
address [gateway] [mask]
Set the VPC's ip, default gateway ip and network mask
Default IPv4 mask is /24, IPv6 is /64. Example:
ip 10.1.1.70/26 10.1.1.65 set the VPC's ip to 10.1.1.70,
the gateway to 10.1.1.65, the netmask to 255.255.255.192.
In tap mode, the ip of the tapx is the maximum host ID
of the subnet. In the example above the tapx ip would be
10.1.1.126
mask may be written as /26, 26 or 255.255.255.192
auto Attempt to obtain IPv6 address, mask and gateway using SLAAC
dhcp [OPTION] Attempt to obtain IPv4 address, mask, gateway, DNS via DHCP
-d Show DHCP packet decode
-r Renew DHCP lease
-x Release DHCP lease
dns ip Set DNS server ip, delete if ip is '0'
domain NAME Set local domain name to NAME
PC1> ip dhcp
DDORA IP 192.168.0.101/24 GW 192.168.0.1
PC1> sho ip
NAME : PC1[1]
IP/MASK : 192.168.0.101/24
GATEWAY : 192.168.0.1
DNS : 8.8.8.8
DHCP SERVER : 192.168.0.1
DHCP LEASE : 86388, 86400/43200/75600
MAC : 00:50:79:66:68:00
LPORT : 10001
RHOST:PORT : 192.168.56.1:10000
MTU: : 1500
Несмотря на то, что VPCS для своей работы требует гораздо меньше оперативной памяти, чем эмулируемый маршрутизатор Cisco серии 7200, далее мы будем использовать именно маршрутизатор даже для выполнения роли клиента DHCP, так как, во-первых, командная строка маршрутизатора нам более привычна, а, во-вторых, мы не стеснены в ресурсах.

R2#conf t
Enter configuration commands, one per line. End with CNTL/Z.
R2(config)#int gi0/0
R2(config-if)#no sh
R2(config-if)#ip add dc
*Aug 14 08:50:40.347: %LINK-3-UPDOWN: Interface GigabitEthernet0/0, changed state to up
*Aug 14 08:50:41.347: %LINEPROTO-5-UPDOWN: Line protocol on Interface GigabitEthernet0/0, changed state to up
R2(config-if)#ip address dhcp
*Aug 14 08:50:59.183: %DHCP-6-ADDRESS_ASSIGN: Interface GigabitEthernet0/0 assigned DHCP address 192.168.0.102, mask 255.255.255.0, hostname R2
R2(config-if)#^Z
R2#sho ip int bri
Interface IP-Address OK? Method Status Protocol
Ethernet0/0 unassigned YES unset administratively down down
GigabitEthernet0/0 192.168.0.102 YES DHCP up up
FastEthernet1/0 unassigned YES unset administratively down down
FastEthernet1/1 unassigned YES unset administratively down down
R2#sho ip ro
Codes: L - local, C - connected, S - static, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2
i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default, U - per-user static route
o - ODR, P - periodic downloaded static route, H - NHRP, l - LISP
+ - replicated route, % - next hop override
Gateway of last resort is 192.168.0.1 to network 0.0.0.0
S* 0.0.0.0/0 [254/0] via 192.168.0.1
192.168.0.0/24 is variably subnetted, 2 subnets, 2 masks
C 192.168.0.0/24 is directly connected, GigabitEthernet0/0
L 192.168.0.102/32 is directly connected, GigabitEthernet0/0
R2#sho ip dns view
DNS View default parameters:
Logging is off
DNS Resolver settings:
Domain lookup is disabled
Default domain name:
Domain search list:
Lookup timeout: 3 seconds
Lookup retries: 2
Domain name-servers:
8.8.8.8
DNS Server settings:
Forwarding of queries is disabled
Forwarder timeout: 3 seconds
Forwarder retries: 2
Forwarder addresses:
Из приведённого выше листинга видно, что маршрутизатор R2 получает IP-адрес 192.168.0.102/24 на интерфейс Gi0/0. Кроме самого адреса с помощью DHCP был передан маршрут по умолчанию и адрес DNS-сервера. Более подробную информацию о работе протокола DHCP на клиентском маршрутизаторе можно получить с помощью команды sho dhcp lease.
R2#sho dhcp lease
Temp IP addr: 192.168.0.102 for peer on Interface: GigabitEthernet0/0
Temp sub net mask: 255.255.255.0
DHCP Lease server: 192.168.0.1, state: 5 Bound
DHCP transaction id: 2155
Lease: 86400 secs, Renewal: 43200 secs, Rebind: 75600 secs
Temp default-gateway addr: 192.168.0.1
Next timer fires after: 11:53:40
Retry count: 0 Client-ID: cisco-ca02.0468.0008-Gi0/0
Client-ID hex dump: 636973636F2D636130322E303436382E
303030382D4769302F30
Hostname: R2
Естественно, доступен и вывод отладочной информации об обмене сообщениями DHCP. Приведённый ниже листинг отображает момент отказа маршрутизатора R2 от арендованного ранее адреса. Вывод отладочных сообщений может быть произведён и на стороне DHCP-сервера, однако стоит отметить, что следует быть особенно осторожным при использовании команды debug в высоконагруженных сетях.
R2#debug dhcp ?
detail DHCP packet content
redundancy DHCP client redundancy support
<cr>
R2#debug dhcp
DHCP client activity debugging is on
R2#conf t
Enter configuration commands, one per line. End with CNTL/Z.
R2(config)#int gi0/0
R2(config-if)#no ip add
*Aug 14 08:59:30.487: DHCP: Sending notification of TERMINATION:
*Aug 14 08:59:30.487: Address 192.168.0.102 mask 255.255.255.0
*Aug 14 08:59:30.491: DHCP: Client socket is opened
*Aug 14 08:59:30.491: DHCP: SRelease attempt # 1 for entry:
*Aug 14 08:59:30.491: DHCP: SRelease placed Server ID option: 192.168.0.1
*Aug 14 08:59:30.495: DHCP: SRelease: 279 bytes
*Aug 14 08:59:32.175: DHCP: SRelease attempt # 2 for entry:
*Aug 14 08:59:32.175: DHCP: SRelease placed Server ID option: 192.168.0.1
*Aug 14 08:59:32.175: DHCP: SRelease: 279 bytes
*Aug 14 08:59:34.175: DHCP: SRelease attempt # 3 for entry:
*Aug 14 08:59:34.175: DHCP: SRelease placed Server ID option: 192.168.0.1
*Aug 14 08:59:34.175: DHCP: SRelease: 279 bytes
R2(config-if)#
*Aug 14 08:59:35.999: RAC: DHCP stopped on interface GigabitEthernet0/0
R2(config-if)#
*Aug 14 09:00:07.207: DHCP: deleting entry 6AF1FA40 192.168.0.102 from list
*Aug 14 09:00:07.207: DHCP: Client socket is closed
R2(config-if)#do sho deb
DHCPC:
DHCP client activity debugging is on
Рассмотрим теперь настройки с серверной стороны, то есть конфигурацию маршрутизатора R1. Первое, что требуется сделать, - запустить соответствующую службу. В современных версиях IOS служба DHCP по умолчанию запущена. Отключить указанную службу можно с помощью команды no service dhcp.
R1(config)#service dhcp
R1(config)#no service dhcp
Вторым шагом является создание DHCP пула с помощью команды ip dhcp pool name, где name – имя создаваемого пула. В листинге ниже на маршрутизаторе R1 создаётся пул foxnetwork, для которого указываются DNS-сервера, шлюз по умолчанию и время аренды. Если в сети планируются какие-либо изменения в ближайшее время, то перед этими изменениями мы бы рекомендовали значительно уменьшать время аренды для того, чтобы пользовательские устройства максимально оперативно отреагировали на произошедшие изменения. Когда топология сети стабилизировалась, время аренды может быть существенно увеличено. Часто время аренды устанавливают равным нескольким дням или даже неделям. В принципе, значение данного параметра выбирается не только из статичности сетевой инфраструктуры, но и с учётом мобильности клиентов. Например, при организации сети в кафе, стоит учитывать, что происходит частая смена посетителей, таким образом, обычно не имеет смысла выставлять время аренды более одного часа. С помощью команды network производится выбор интерфейса, к которому привязан данный пул, а также указание диапазона адресов, который используется для назначения клиентам. Исключить какие-либо IP-адреса из диапазона можно с помощью команды ip dhcp excluded-address режима глобальной конфигурации.
ip dhcp excluded-address 192.168.0.1 192.168.0.100
ip dhcp pool foxnetwork
network 192.168.0.0 255.255.255.0
lease 1
default-router 192.168.0.1
dns-server 8.8.8.8
Посмотреть список созданных пулов и их использование можно с помощью команды sho ip dhcp pool.
R1#sho ip dhcp pool
Pool foxnetwork :
Utilization mark (high/low) : 100 / 0
Subnet size (first/next) : 0 / 0
Total addresses : 254
Leased addresses : 1
Pending event : none
1 subnet is currently in the pool :
Current index IP address range Leased addresses
192.168.0.102 192.168.0.1 - 192.168.0.254 1
Команда sho ip dhcp binding отображает список адресов, которые были назначены клиентам.
R1#sho ip dhcp binding
Bindings from all pools not associated with VRF:
IP address Client-ID/ Lease expiration Type
Hardware address/
User name
192.168.0.101 0063.6973.636f.2d63. Aug 21 2015 09:46 AM Automatic
6130.322e.3034.3638.
2e30.3030.382d.4769.
302f.30
Статистические сведения о работе службы DHCP на маршрутизаторе можно получить с помощью команды sho ip dhcp server statistics.
R1#sho ip dhcp server statistics
Memory usage 73238
Address pools 1
Database agents 0
Automatic bindings 1
Manual bindings 0
Expired bindings 0
Malformed messages 0
Secure arp entries 0
Message Received
BOOTREQUEST 0
DHCPDISCOVER 5
DHCPREQUEST 4
DHCPDECLINE 0
DHCPRELEASE 6
DHCPINFORM 0
Message Sent
BOOTREPLY 0
DHCPOFFER 4
DHCPACK 4
DHCPNAK 0
Иногда в корпоративных сетях возникает необходимость статической привязки выдаваемого IP-адреса к определённому клиенту. Такую привязку можно осуществить на основе идентификатора клиента, передаваемого в опции №61. Сравните значение опции №61 в сообщениях DHCP discovery, отправляемых разными DHCP-клиентами. Пример DHCP discovery, отправляемый маршрутизатором Cisco, содержится в файле foxnetwork_1.pcapng, то же сообщение от Microsoft Windows 7 находится в файле foxnetwork_3.pcapng. Таким образом, перед началом создания статической привязки IP-адреса к клиенту, нужно выяснить значение идентификатора, отправляемого операционной системой клиента. После того, как идентификатор клиента выяснен, необходимо перейти к настройке DHCP-сервера, работающего на маршрутизаторе. Статическая привязка организуется путём создания нового DHCP-пула, в котором требуется лишь указать адрес, выдаваемый клиенту, и идентификатор клиента. Также можно указать имя клиента с помощью команды client-name (не передаётся клиенту в сообщениях DHCP). Пример такого пула представлен ниже.
ip dhcp pool r2
host 192.168.0.111 255.255.255.0
client-identifier 0063.6973.636f.2d63.6130.322e.3135.3063.2e30.3030.382d.4769.302f.30
client-name test
Все остальные настройки (кроме IP-адреса) клиент наследует из родительского пула. Стоит также отметить, что наследование настроек происходит и при использовании обычных пулов. Рассмотрим небольшой сегмент сети, представленный на схеме.
В листинге ниже мы создали два пула для вложенных диапазонов: 192.168.0.0/16 и 192.168.0.0/24. Для большой подсети задана единственная настройка – адрес DNS-сервера. Пул с более мелкой подсетью содержит адрес шлюза по умолчанию.
ip dhcp pool parent
network 192.168.0.0 255.255.0.0
dns-server 8.8.8.8
ip dhcp pool child
network 192.168.0.0 255.255.255.0
default-router 192.168.0.1
R1#sho ip int bri
Interface IP-Address OK? Method Status Protocol
Ethernet0/0 unassigned YES unset administratively down down
GigabitEthernet0/0 192.168.0.1 YES manual up up
Убедиться, что клиент (роль которого выполняет узел VPCS) получает все необходимые настройки можно с помощью команды show ip.
PC1> sho ip
NAME : PC1[1]
IP/MASK : 192.168.0.2/24
GATEWAY : 192.168.0.1
DNS : 8.8.8.8
DHCP SERVER : 192.168.0.1
DHCP LEASE : 86397, 86400/43200/75600
MAC : 00:50:79:66:68:00
LPORT : 10000
RHOST:PORT : 192.168.228.2:10001
MTU: : 1500
Для закрепления материала рекомендуем начинающим читателям выполнить соответствующую лабораторную работу.
Процесс назначения IP-адреса
Ранее мы рассмотрели команду ip dhcp excluded-address, позволяющую исключить диапазон адресов из выдачи. Такое исключение будет полезным, когда в одной IP-подсети находятся как динамически конфигурируемые клиенты, так и узлы со статической конфигурацией, например, интерфейсы сетевого оборудования или сервера. Но что если в сети окажется статически сконфигурированное устройство, адрес которого выходит за пределы исключаемого диапазона? Для обнаружения подобных ситуаций, служба DHCP, работающая на маршрутизаторе Cisco, использует протокол ICMP. Вероятно, некоторые наши читатели удивятся, узнав, что используется ICMP echo, а не ARP. Да-да, используется именно ICMP и в дальнейшем станет понятно, почему. Рассмотрим на примерах, что именно происходит в момент выдачи адреса клиенту.
Для начала используем простую схему с двумя маршрутизаторами R1 и R2, которую мы уже применяли ранее. R1 выполняет функции сервера, а R2 – клиента. Все пакеты, которыми обмениваются два устройства, мы сохранили в файле foxnetwork_4.pcapng. Первый пакет отправляется клиентом - это обычный gratuitous ARP, за которым следует широковещательное сообщение DHCP discover. Третий пакет – ARP-запрос DHCP-сервера об адресе 192.168.0.102. Следующие три пакета – обычное окончание DHCP обмена. Но что это за адрес 192.168.0.102? Из четвёртого пакета (DHCP offer) понятно, что это адрес, предлагаемый сервером клиенту. Получается, что перед тем, как выдать адрес, сервер рассылает ARP-запрос. Но никакого ICMP, верно? Что ж, попробуем разместить в сети узел с IP-адресом, который планирует выдать R1. Наша сеть несколько изменится.
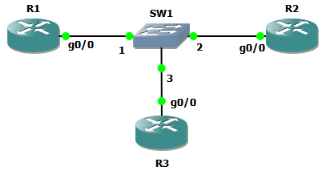
Мы добавили маршрутизатор R3, на интерфейс Gi0/0 которого назначили IP-адрес 192.168.0.103, который должен быть выдан при следующем DHCP-запросе к маршрутизатору R1. Следующий выдаваемый адрес отображается в выводе команды sho ip dhcp pool в поле Current index. Мы перехватили процесс обмена сообщениями при получении адреса маршрутизатором R2 и сохранили его в файле foxnetwork_5.pcapng. По дампу трафика видно, что маршрутизатор R1, получив запрос DHCP, отправляет ARP-запрос об адресе 192.168.0.103, а после получения ответа, отправляет сообщение ICMP echo-request, в ответ на которое R3 отправляет ICMP echo-reply. После получения эхо-ответа маршрутизатор R1 проверяет на занятость следующий адрес – 192.168.0.104. Убедившись в том, что данный адрес свободен, R1 предлагает его клиенту. Итак, мы увидели, что при выборе адреса для клиента DHCP-сервер проверяет занятость этого адреса с помощью ICMP. Маршрутизаторы Cisco Systems, выполняющие функции DHCP-сервера позволяют даже произвести настройку количества отправляемых ICMP эхо-запросов и их таймауты.
R1(config)#ip dhcp ping ?
packets Specify number of ping packets
timeout Specify ping timeout
R1(config)#ip dhcp ping pa
R1(config)#ip dhcp ping packets ?
<0-10> Number of ping packets (0 disables ping)
<cr>
R1(config)#ip dhcp ping ti
R1(config)#ip dhcp ping timeout ?
<100-10000> Ping timeout in milliseconds
Остаётся единственный вопрос: что будет делать DHCP-сервер, если получит ARP-ответ, но не получит ICMP echo-reply? Попробуем воспроизвести данную ситуацию. Для того чтобы запретить маршрутизатору R3 отвечать на ICMP-запросы, требуется создать список доступа, запрещающий ICMP эхо, а также ввести команду no ip unreachables на интерфейсе Gi0/0. Список доступа и конфигурация интерфейса Gi0/0 маршрутизатора R3 представлены в листинге ниже. Хотелось бы обратить внимание читателей на то, что мы также изменили IP-адрес интерфейса, так как следующим предлагаемым по DHCP адресом должен быть 192.168.0.105.
ip access-list extended NOICMP
deny icmp any any
permit ip any any
interface GigabitEthernet0/0
ip address 192.168.0.105 255.255.255.0
ip access-group NOICMP in
no ip unreachables
duplex full
speed 1000
media-type gbic
negotiation auto
И что же будет теперь, если допустить, что DHCP-сервис маршрутизаторов Cisco полагается именно на ICMP? При использовании приведённой конфигурации, R2 должен получить адрес, уже назначенный маршрутизатору R3. К счастью, этого не происходит, так как перед началом использования предлагаемого DHCP-сервером адреса клиент проверяет наличие такого адреса в сети именно с помощью протокола ARP. Все сообщения, которыми обмениваются маршрутизаторы, представлены в файле foxnetwork_6.pcapng. Последовательность действий узлов в сети следующая.
- R2 отправляет сообщение DHCP discover.
- R1 с помощью ICMP проверяет занятость адреса 192.168.0.105.
- Во время такой проверки R3 отвечает на ARP-запрос (что делает возможной отправку сообщения ICMP), но не отвечает на сообщение ICMP echo-request.
- Маршрутизатор R1, не получив никакого ICMP сообщения от узла с адресом 192.168.0.105, предлагает его использование клиенту R2 при помощи сообщения DHCP offer.
- Клиент R2 получает сообщение DHCP offer от сервера R1, содержащее предлагаемый IP-адрес, после чего выполняет собственную проверку занятости адреса 192.168.0.105 с помощью протокола ARP.
- Узел R3 отвечает на ARP-запрос маршрутизатора R2.
- R2 считает, что предложенный сервером IP-адрес 192.168.0.105 уже занят, и отправляет серверу уведомление об этом с помощью сообщения DHCP decline.
- R1 вносит адрес 192.168.0.105 в свою базу конфликтующих адресов.
- R2 вновь инициирует поиск сервера DHCP путём отправки сообщения DHCP discover.
- Сервер R1 выбирает следующий адрес из пула – 192.168.0.106 – и проверяет, не занят ли он.
- Сервер R1 предлагает адрес 192.168.0.106 клиенту R2 с помощью сообщения DHCP offer.
- Клиент R2 запрашивает у сервера разрешение на использование адреса 192.168.0.106 при помощи сообщения DHCP request.
- Сервер R1 подтверждает использование клиентом R2 адреса 192.168.0.106 с помощью сообщения DHCP ack.
- Маршрутизатор R2 выполняет собственную проверку занятости нового адреса и убеждается, что он свободен.
Стоп-стоп-стоп! Что-то в этом списке не так. Судя по дампу, после отправки второго сообщения DHCP discover клиент не выполняет проверку занятости предлагаемого адреса, а сразу принимает его, после чего рассылает сообщение gratuitous ARP. Мы повторили процесс ещё раз, назначив узлу R3 адрес 192.168.0.107. Ошибки быть не может, всё именно так и происходит. Но что же будет, если повторно полученный адрес окажется также занятым? Мы добавили в нашу схему ещё один хост со следующим по порядку адресом, таким образом у нас в сети сейчас присутствует узел R3 с адресом 192.168.0.109, и R4 – 192.168.0.110, которые не отвечают на ICMP-сообщения.
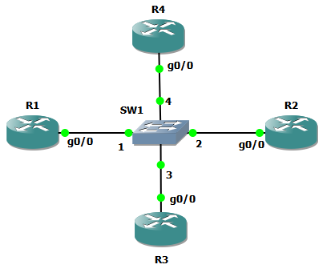
Мы вновь инициировали процедуру получения IP-адреса маршрутизатором R2. Дамп трафика мы сохранили в файле foxnetwork_7.pcapng. Получается, что получив IP-адрес второй раз, клиент назначает его на свой интерфейс, отправляет gratuitous ARP, обнаруживает занятость данного адреса, после чего проводит стандартную процедуру отказа от полученного адреса с помощью сообщения DHCP decline. На узлах R3 и R4 в этот момент появляются следующие сообщения.
*Aug 14 15:22:04.751: %IP-4-DUPADDR: Duplicate address 192.168.0.110 on GigabitEthernet0/0, sourced by ca02.150c.0008
Просмотреть список конфликтующих адресов на R1 можно с помощью команды sho ip dhcp conflict.
R1#sho ip dhcp conflict
IP address Detection method Detection time VRF
192.168.0.103 Ping Aug 14 2015 01:12 PM
192.168.0.105 Gratuitous ARP Aug 14 2015 02:15 PM
192.168.0.107 Gratuitous ARP Aug 14 2015 03:16 PM
192.168.0.109 Gratuitous ARP Aug 14 2015 03:22 PM
192.168.0.110 Gratuitous ARP Aug 14 2015 03:22 PM
Очистка базы конфликтующих адресов производится с помощью команды clear ip dhcp conflict.
R1#clear ip dhcp conflict ?
* Clear all address conflicts
A.B.C.D Clear a specific conflict
vrf DHCP vrf conflicts
R1#clear ip dhcp conflict *
R1#sho ip dhcp conflict
IP address Detection method Detection time VRF
R1#
На этом мы завершаем рассмотрение процедуры получения IP-параметров и переходим к рассмотрению использования вторичных IP-подсетей совместно с протоколом DHCP.
Secondary subnet
С увеличением количества IP-устройств в сети может возникнуть нехватка IP-адресов в пуле. Конечно, в некоторых случаях с данной проблемой можно справиться путём уменьшения времени аренды IP-адреса, однако ситуации, когда все устройства длительное время находятся во включённом состоянии, нередки. Выхода из сложившейся ситуации два: увеличение ранее выделенной подсети и использование второй подсети. К сожалению, увеличение подсети не всегда возможно, например, из-за отсутствия непрерывных подсетей большего размера. Рассмотрим настройку оборудования для использования вторичной подсети на примере сети, представленной ниже. Будем считать, что изначально для связи узла PC1 и маршрутизатора R1 использовалась подсеть 192.168.0.0/30. После появления узла PC2 существующего диапазона, очевидно, стало недостаточно.
В листинге ниже представлены основные настройки маршрутизатора R1, до появления хоста PC2. Интерфейс Loopback 0 используется для эмуляции глобальной сети.
ip dhcp pool foxnetwork
network 192.168.0.0 255.255.255.252
default-router 192.168.0.1
dns-server 8.8.8.8
domain-name foxnetwork.ru
lease 0 1
interface Loopback0
ip address 1.1.1.1 255.255.255.255
interface GigabitEthernet0/0
ip address 192.168.0.1 255.255.255.252
load-interval 30
Первое, с чего, естественно, требуется начать, - это настройка интерфейса маршрутизатора или L3-коммутатора, на интерфейсе которого необходимо прописать вторичный IP-адрес.
R1#sho run int gi0/0
Building configuration...
Current configuration : 204 bytes
interface GigabitEthernet0/0
ip address 192.168.1.1 255.255.255.252 secondary
ip address 192.168.0.1 255.255.255.252
load-interval 30
end
Одним из способов использования DHCP-сервером вторичной подсети является создание второго DHCP-пула.
ip dhcp pool foxnetwork2
network 192.168.1.0 255.255.255.252
dns-server 8.8.8.8
domain-name foxnetwork.ru
default-router 192.168.1.1
lease 0 1
Кроме создания второго пула существует и более элегантное решение, состоящее в указании наличия вторичной сети в настройках существующего пула адресов.
R1#sho run | sec pool
ip dhcp pool foxnetwork
network 192.168.0.0 255.255.255.252
network 192.168.1.0 255.255.255.252 secondary
override default-router 192.168.1.1
default-router 192.168.0.1
dns-server 8.8.8.8
domain-name foxnetwork.ru
lease 0 1
Стоит, правда, отметить, что для вторичной сети в настройках DHCP-пула можно изменить лишь значение шлюза по умолчанию. Если требуется, чтобы различались какие-либо ещё параметры, единственным решением на данный момент является создание второго DHCP-пула.
Осталось только проверить работоспособность приведённой выше конструкции.
PC2> ip dh
DDORA IP 192.168.1.2/30 GW 192.168.1.1
PC2> sho ip
NAME : PC2[1]
IP/MASK : 192.168.1.2/30
GATEWAY : 192.168.1.1
DNS : 8.8.8.8
DHCP SERVER : 192.168.0.1
DHCP LEASE : 3599, 3600/1800/3150
DOMAIN NAME : foxnetwork.ru
MAC : 00:50:79:66:68:01
LPORT : 10004
RHOST:PORT : 192.168.56.1:10005
MTU: : 1500
PC2> sho ip all
NAME IP/MASK GATEWAY MAC DNS
PC2 192.168.1.2/30 192.168.1.1 00:50:79:66:68:01 8.8.8.8
PC2> sho arp
ca:01:5f:7c:00:08 192.168.1.1 expires in 37 seconds
PC2> ping 192.168.1.1 -c 3
84 bytes from 192.168.1.1 icmp_seq=1 ttl=255 time=9.000 ms
84 bytes from 192.168.1.1 icmp_seq=2 ttl=255 time=9.000 ms
84 bytes from 192.168.1.1 icmp_seq=3 ttl=255 time=9.000 ms
PC2> ping 192.168.0.1 -c 3
84 bytes from 192.168.0.1 icmp_seq=1 ttl=255 time=5.001 ms
84 bytes from 192.168.0.1 icmp_seq=2 ttl=255 time=9.001 ms
84 bytes from 192.168.0.1 icmp_seq=3 ttl=255 time=9.000 ms
PC2> ping 192.168.0.2 -c 3
84 bytes from 192.168.0.2 icmp_seq=1 ttl=63 time=11.001 ms
84 bytes from 192.168.0.2 icmp_seq=2 ttl=63 time=19.001 ms
84 bytes from 192.168.0.2 icmp_seq=3 ttl=63 time=19.002 ms
PC2> ping 1.1.1.1 -c 3
84 bytes from 1.1.1.1 icmp_seq=1 ttl=255 time=4.000 ms
84 bytes from 1.1.1.1 icmp_seq=2 ttl=255 time=9.001 ms
84 bytes from 1.1.1.1 icmp_seq=3 ttl=255 time=9.000 ms
Очевидным недостатком использования вторичных сетей (вместо увеличения существующей сети) является необходимость использования маршрутизатора для передачи трафика между узлами, расположенными в первичной и вторичных IP-сетях. Использование двух и более IP-сетей в данном случае не приводит к уменьшению широковещательного трафика, что также, возможно, стоит учитывать при построении крупных корпоративных сетей. В этом случае, вероятно, лучше использовать несколько виртуальных сетей (VLAN) и различные DHCP-пулы. Ещё одно замечание, которое хотелось бы здесь привести, связано с использованием многоуровневых коммутаторов. Если используется единственное MLS устройство, которое выполняет функции маршрутизации, коммутации и DHCP-сервера, в этом случае увеличением задержек и падением производительности сети (из-за необходимости маршрутизировать трафик между узлами в первичной и вторичных IP-сетях) можно пренебречь.
При обсуждении особенностей использования вторичных IP-сетей на интерфейсах нельзя не упомянуть о команде ip dhcp smart-relay, влияющей на работу маршрутизатора, выполняющего функции ретранслятора DHCP и использующего вторичные IP-адреса на интерфейсах. Рассмотрим в качестве примера небольшую сеть, представленную на рисунке ниже.

Маршрутизатор R1 является ретранслятором DHCP, тогда как маршрутизатор R2 выполняет функции DHCP-сервера. Допустим, что на интерфейсе Fa1/0 маршрутизатора R1 настроены две IP-сети. Пример настройки интерфейса Fa1/0 маршрутизатора R1 представлен ниже. Адрес 2.2.2.2 назначен на интерфейсе Loopback 0 маршрутизатора R2. Считаем, что на обоих маршрутизаторах маршрутизация настроена правильно.
interface FastEthernet1/0
ip address 192.168.1.1 255.255.255.0 secondary
ip address 192.168.0.1 255.255.255.0
ip helper-address 2.2.2.2
На маршрутизаторе R2 настроен DHCP-пул.
ip dhcp excluded-address 192.168.1.1 192.168.1.10
ip dhcp pool foxnetwork
network 192.168.1.0 255.255.255.0
default-router 192.168.1.1
dns-server 8.8.8.8
lease 0 1
По умолчанию, маршрутизатор R1 пересылает сообщение DHCP discover с первичного IP-адреса, настроенного на интерфейсе Fa1/0. Так как на устройстве R2 нет DHCP-пула для сети 192.168.0.0/24, сообщение DHCP offer отправлено не будет, что приведёт к тому, что клиентский узел PC1 не получит IP-адрес. Включение опции smart-relay заставляет маршрутизатор R1 после отправки трёх сообщений с первичного IP-адреса, отправлять сообщения DHCP discover с адреса вторичной сети в ситуации, когда на первые три сообщения не было получено сообщения DHCP offer. Перехват сообщений DHCP между маршрутизаторами R1 и R2 мы сохранили в файл foxnetwork_13.pcapng. Читателям стоит обратить внимание на поле «Relay agent IP address» в сообщениях DHCP discover.
С точки зрения маршрутизации первичная и вторичные сети ничем принципиальным не отличаются. Здесь мы не рассматриваем использование протоколов динамической маршрутизации, некоторые из которых не могут установить соседство с другими маршрутизаторами, расположенными во вторичных IP-сетях.
R1#sho ip ro
Codes: L - local, C - connected, S - static, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2
i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default, U - per-user static route
o - ODR, P - periodic downloaded static route, H - NHRP, l - LISP
+ - replicated route, % - next hop override
Gateway of last resort is not set
1.0.0.0/32 is subnetted, 1 subnets
C 1.1.1.1 is directly connected, Loopback0
192.168.0.0/24 is variably subnetted, 2 subnets, 2 masks
C 192.168.0.0/30 is directly connected, GigabitEthernet0/0
L 192.168.0.1/32 is directly connected, GigabitEthernet0/0
192.168.1.0/24 is variably subnetted, 2 subnets, 2 masks
C 192.168.1.0/30 is directly connected, GigabitEthernet0/0
L 192.168.1.1/32 is directly connected, GigabitEthernet0/0
Рассмотрим теперь, какие ещё возможности предоставляет оборудование компании Cisco по работе с протоколом DHCP.
Дополнительные возможности: relay
Все схемы, обсуждавшиеся выше, предполагали установку DHCP-сервера непосредственно в пользовательский сегмент. Конечно же, использование многоуровневого коммутатора в качестве DHCP-сервера также допустимо, однако при использовании MLS оборудования эксплуатация IPAM систем, к числу которых относится и решение для управления сетями Cisco Network Registrar (CNR), может быть затруднена или вовсе невозможна. Существует ли технология, позволяющая не подключать DHCP-сервер к каждому пользовательскому сегменту и при этом не заставлять коммутаторы и маршрутизаторы заниматься распределением IP-адресов? Такая функция, конечно же, существует и называется DHCP relay. Оборудование, выполняющее роль DHCP-ретранслятора, перехватывает широковещательные сообщения DHCP discover и пересылает их DHCP-серверу. Включение поддержки функции ретранслятора производится с помощью интерфейсной команды ip helper-address. Рассмотрим небольшую схему, приведённую ниже.

Узел PC1 является DHCP-клиентом. Маршрутизатор R1 терминирует на себе клиентскую сеть и выполняет функции ретранслятора. DHCP-сервером является маршрутизатор R2. Приведём основные параметры конфигурации обоих маршрутизаторов. На устройстве R1 введены следующие команды.
interface Loopback0
ip address 192.168.255.1 255.255.255.255
interface FastEthernet1/0
ip address 192.168.0.1 255.255.255.0
ip helper-address 192.168.255.2
interface FastEthernet1/1
ip address 192.168.1.1 255.255.255.0
router eigrp 1
network 192.168.1.0
redistribute connected
Конфигурация маршрутизатора R2 представлена ниже.
ip dhcp excluded-address 192.168.0.1 192.168.0.10
ip dhcp pool foxnetwork
network 192.168.0.0 255.255.255.0
default-router 192.168.0.1
dns-server 8.8.8.8
lease 0 1
interface Loopback0
ip address 192.168.255.2 255.255.255.255
interface FastEthernet1/1
ip address 192.168.1.2 255.255.255.0
router eigrp 1
network 192.168.1.0
redistribute connected
Процесс получения IP-адреса клиентом с использованием ретранслятора не отличается от такового при размещении DHCP-сервера непосредственно в сети клиента.
PC1> ip dhcp
DDORA IP 192.168.0.11/24 GW 192.168.0.1
PC1> sho ip
NAME : PC1[1]
IP/MASK : 192.168.0.11/24
GATEWAY : 192.168.0.1
DNS : 8.8.8.8
DHCP SERVER : 192.168.1.2
DHCP LEASE : 3595, 3600/1800/3150
MAC : 00:50:79:66:68:00
LPORT : 10000
RHOST:PORT : 192.168.56.1:10001
MTU: : 1500
PC1> ping 192.168.255.2
84 bytes from 192.168.255.2 icmp_seq=1 ttl=254 time=29.002 ms
84 bytes from 192.168.255.2 icmp_seq=2 ttl=254 time=29.002 ms
84 bytes from 192.168.255.2 icmp_seq=3 ttl=254 time=16.001 ms
84 bytes from 192.168.255.2 icmp_seq=4 ttl=254 time=21.001 ms
84 bytes from 192.168.255.2 icmp_seq=5 ttl=254 time=32.002 ms
Естественно, мы перехватили процесс получения клиентом IP-адреса. В файле foxnetwork_11.pcapng находятся пакеты, передаваемые между клиентом и маршрутизатором R1, тогда как файл foxnetwork_12.pcapng содержит трафик, которым обменивались маршрутизаторы R1 и R2. Как видно из дампа foxnetwork_12.pcapng обмен DHCP сообщениями между маршрутизаторами происходит с помощью unicast-адресов. Мы рекомендуем читателям сравнить значение поля «Relay agent IP address» в обоих файлах. Также небезынтересным является ICMP трафик, отправляемый DHCP-сервером в процессе получения IP-адреса клиентом. В предыдущем разделе мы описывали алгоритмы, используемые сервером DHCP, для определения занятости IP-адреса до предложения его клиенту. Так вот, протокол ARP в данном случае, очевидно, не может быть использован совершенно, так как передача ARP-сообщений через маршрутизатор не производится.
Стоит отметить, что по умолчанию, команда ip helper-address пересылает не только DHCP сообщения, но и целый ряд других. Отключить ретрансляцию протокола можно с помощью команды no ip forward-protocol.
switch(config)#no ip forward-protocol ?
nd Sun's Network Disk protocol
sdns Network Security Protocol
spanning-tree Use transparent bridging to flood UDP broadcasts
turbo-flood Fast flooding of UDP broadcasts
udp Packets to a specific UDP port
switch(config)#no ip forward-protocol udp ?
<0-65535> Port number
biff Biff (mail notification, comsat, 512)
bootpc Bootstrap Protocol (BOOTP) client (68)
bootps Bootstrap Protocol (BOOTP) server (67)
discard Discard (9)
dnsix DNSIX security protocol auditing (195)
domain Domain Name Service (DNS, 53)
echo Echo (7)
isakmp Internet Security Association and Key Management Protocol (500)
mobile-ip Mobile IP registration (434)
nameserver IEN116 name service (obsolete, 42)
netbios-dgm NetBios datagram service (138)
netbios-ns NetBios name service (137)
netbios-ss NetBios session service (139)
non500-isakmp Internet Security Association and Key Management Protocol (4500)
ntp Network Time Protocol (123)
pim-auto-rp PIM Auto-RP (496)
rip Routing Information Protocol (router, in.routed, 520)
snmp Simple Network Management Protocol (161)
snmptrap SNMP Traps (162)
sunrpc Sun Remote Procedure Call (111)
syslog System Logger (514)
tacacs TAC Access Control System (49)
talk Talk (517)
tftp Trivial File Transfer Protocol (69)
time Time (37)
who Who service (rwho, 513)
xdmcp X Display Manager Control Protocol (177)
<cr>
Также мы не можем не упомянуть здесь об одной, возможно, не самой очевидной детали: на маршрутизаторе, выполняющем функции ретранслятора DHCP, должна быть включена служба DHCP. Включение службы производится с помощью команды service dhcp, для отключения используйте команду no service dhcp. В маршрутизаторах Cisco данная служба включена автоматически и в запущенном состоянии даже не отображается в текущем конфиге.
R2#sho run | i dhcp
R2#conf t
Enter configuration commands, one per line. End with CNTL/Z.
R2(config)#no serv dhcp
R2(config)#^Z
R2#sho run | i dhcp
no service dhcp
R2#
Администратор может также настроить поведение ретранслятора DHCP при получении DHCP сообщения, содержащего информацию о другом ретрансляторе. Указанные сообщения могут быть отброшены, инкапсулированы (DHCP-сервер, в принципе, может использовать обе опции №82), пересланы без изменений, либо информация о ретрансляторе может быть заменена.
switch(config)#ip dhcp relay information policy ?
drop Do not forward BOOTREQUEST message
encapsulate Encapsulate existing information
keep Leave existing information alone
replace Replace existing information
Очень тесно с темой DHCP ретранслятора связаны поддержка опции №82 и DHCP snooping, о которых мы поговорим в следующем разделе.
Дополнительные возможности: option 82, snooping
До этого момента мы никак не настраивали коммутатор, связывающий клиента и маршрутизатор R1, единственное, что требовалось, - чтобы порты e0/0 и e0/1 находились в одной виртуальной сети. Однако периодически возникает необходимость определённому клиенту выдавать фиксированный адрес с помощью DHCP. Задача осложняется тем, что клиент может использовать различные устройства для подключения к сети, таким образом его MAC-адрес и идентификатор клиента могут отличаться, что не позволит использовать данные поля DHCP-сервером для создания статической привязки. В этом случае на помощь приходит коммутатор с поддержкой функции option 82. Данную опцию ото всех остальных отличает то, что её в DHCP сообщение добавляет не клиент и не сервер, а коммутатор, тогда как сервер DHCP анализирует её значение. К счастью L2 IOU версии adventerprisek9-15.1a поддерживает данную функцию. Включение поддержки option 82 производится с помощью команды ip dhcp relay information option режима глобальной конфигурации. Также необходимо включить DHCP snooping. Ниже представлены команды, которые были введены на коммутаторе.
ip dhcp relay information option
ip dhcp snooping vlan 1
ip dhcp snooping
interface Ethernet0/1
ip dhcp snooping trust
Мы перехватили сообщение DHCP discover на участке сети между коммутатором IOU1 и маршрутизатором R1. Как видно из представленной ниже картинки, коммутатор добавил в сообщение опцию №82. Её содержимое мы пока не рассматриваем.
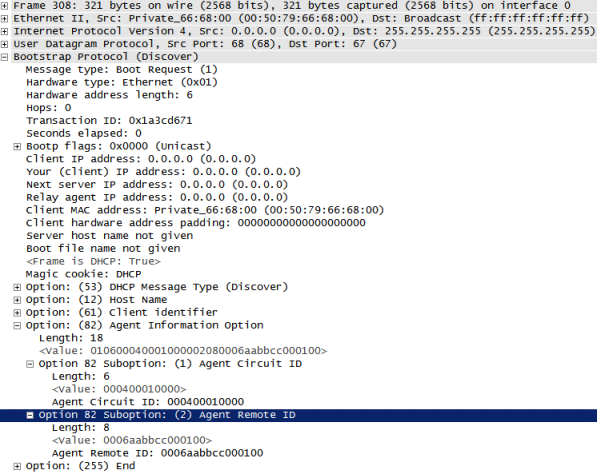
Однако, несмотря на то, что мы увидели сообщение DHCP discover в сети, клиент перестал получать IP-адрес. Просмотр дампа трафика нас приводит к тому, что маршрутизатор R1 перестал выполнять функции ретранслятора. Неожиданно, правда? С помощью команды deb ip dhcp server packet мы включили вывод отладочной информации на маршрутизаторе DHCP. В момент получения пакета, содержащего сообщение DHCP discover, в консоли появлялись следующие сообщения, - сработала так называемая санитарная проверка.
*Aug 21 18:28:28.247: DHCPD: inconsistent relay information.
*Aug 21 18:28:28.247: DHCPD: relay information option exists, but giaddr is zero
Отключение указанной выше проверки производится на интерфейсе Fa1/0 маршрутизатора R1 с помощью команды ip dhcp relay information trusted, после чего клиент успешно получает IP-адрес. Список интерфейсов, для которых включена данная команда выводится с помощью вызова sho ip dhcp relay information trusted-sources.
R1#sho ip dhcp relay information trusted-sources
List of trusted sources of relay agent information option:
FastEthernet1/0
Выдача адреса клиенту на данный момент никак не учитывает значение опции №82. Для того чтобы DHCP-сервер начал учитывать значение опции №82 необходимо сконфигурировать специальный класс для данного клиента. Пример такой конфигурации представлен ниже.
ip dhcp class foxnetwork
remark test client
relay agent information
relay-information hex 010600040001000002080006aabbcc000100
Команда remark не является обязательной, однако мы настоятельно рекомендуем использовать, чтобы в дальнейшем не запутаться в большом количестве созданных классов. С помощью данной команды нужно вносить максимально понятное описание, связанное с клиентом, для которого создаётся класс.
Теперь требуется использовать созданный класс в настройках DHCP-сервера. Конфигурация DHCP пула представлена ниже.
ip dhcp pool foxnetwork
network 192.168.0.0 255.255.255.0
default-router 192.168.0.1
dns-server 8.8.8.8
lease 0 1
class foxnetwork
address range 192.168.0.101 192.168.0.101
Повторно произведём получение IP-адреса клиентом и убедимся, что PC1 получил адрес 192.168.0.101.
PC1> sho ip
NAME : PC1[1]
IP/MASK : 192.168.0.11/24
GATEWAY : 192.168.0.1
DNS : 8.8.8.8
DHCP SERVER : 192.168.1.2
DHCP LEASE : 2753, 3600/1800/3150
MAC : 00:50:79:66:68:00
LPORT : 10003
RHOST:PORT : 192.168.56.1:10000
MTU: : 1500
PC1> ip dhcp
DDORA IP 192.168.0.101/24 GW 192.168.0.1
PC1> sho ip
NAME : PC1[1]
IP/MASK : 192.168.0.101/24
GATEWAY : 192.168.0.1
DNS : 8.8.8.8
DHCP SERVER : 192.168.1.2
DHCP LEASE : 3593, 3600/1800/3150
MAC : 00:50:79:66:68:00
LPORT : 10003
RHOST:PORT : 192.168.56.1:10000
MTU: : 1500
Но что же это за магическое число 010600040001000002080006aabbcc000100, которое мы указывали в команде relay-information и которое передавалось в опции №82? Разберём, из чего оно состоит.
| 010600040001000002080006aabbcc000100 | |
| 0106 | Начало первой секции, 6 байт |
| 0004 | Поле curcuit-id, 4 байта |
| 0001 | Номер VLAN (в hex) |
| 0000 | Номер порта коммутатора, к которому подключен клиент (счёт начинается с нуля) |
| 0208 | Начало второй секции, 8 байт |
| 0006 | Поле remote-id, 6 байт |
| aabbcc000100 | MAC-адрес коммутатора, к которому подключен клиент |
Теперь мы можем рассчитывать значение опции №82 заранее, не дожидаясь её в перехватываемых пакетах. Справедливости ради, стоит отметить, что коммутаторы Cisco позволяют изменить формат опции №82.
cisco_3750(config)#ip dhcp snooping information option format remote-id ?
hostname Use configured hostname for remote id
string User defined string for remote id
cisco_3750(config)#ip dhcp snooping information option format remote-id hostname ?
<cr>
cisco_3750(config)#ip dhcp snooping information option format remote-id string ?
WORD Use string for remote id (max length 63)
При настройке коммутатора в данной секции, мы задействовали функции DHCP-snooping. Но для чего она предназначена? Функция коммутатора DHCP-snooping предназначена для защиты от атак с использованием протокола DHCP. Примером таких атак может быть подмена DHCP-сервера или же атака DHCP starvation, в результате которой атакующий заставляет DHCP-сервер выдать злоумышленнику все доступные IP-адреса. Построенная в результате работы функции DHCP snooping база данных может использоваться и другими механизмами защиты, к числу которых относятся DAI (Dynamic ARP Inspection) и IP Source Guide. Правда, обсуждение работы данных функций выходит далеко за пределы темы данной статьи.
Функция DHCP snooping определяет для всех портов две роли: доверенный/надёжный (trusted) и ненадёжный (untrusted). К доверенным портам подключают другие коммутаторы или DHCP-серверы, DHCP-сообщения, полученные через эти порты, не отбрасываются. DHCP-трафик от ненадёжных портов инспектируется, а сообщения DHCP offer, ack/nack и leasequery отбрасываются. Инспекция DHCP-трафика от ненадёжных портов заключается, например, в следующем: проверяются сообщения DHCP release и decline на соответствие базе, проверяется соответствие MAC-адресов во фрейме и самом сообщении DHCP, устанавливается отсутствие опции №82. Также можно заставить коммутаторы выполнять проверку DHCP-сообщений на отсутствие в сообщении адреса ретранслятора.
IOU1(config)#ip dhcp snooping verify ?
mac-address DHCP snooping verify mac-address
no-relay-agent-address DHCP snooping verify giaddr
Просмотр настроек функции DHCP snooping производится с помощью команды show ip dhcp snooping.
IOU1#sho ip dhcp snooping
Switch DHCP snooping is enabled
DHCP snooping is configured on following VLANs:
1
DHCP snooping is operational on following VLANs:
1
DHCP snooping is configured on the following L3 Interfaces:
Insertion of option 82 is enabled
circuit-id default format: vlan-mod-port
remote-id: aabb.cc00.0100 (MAC)
Option 82 on untrusted port is not allowed
Verification of hwaddr field is enabled
Verification of giaddr field is enabled
DHCP snooping trust/rate is configured on the following Interfaces:
Interface Trusted Allow option Rate limit (pps)
----------------------- ------- ------------ ----------------
Ethernet0/1 yes yes unlimited
Custom circuit-ids:
Команда show ip dhcp snooping statistics отображает статистические сведения о работе DHCP snooping.
IOU1#sho ip dhcp snooping statistics
Packets Forwarded = 229
Packets Dropped = 0
Packets Dropped From untrusted ports = 0
Просмотреть существующие в данный момент привязки можно с помощью команды show ip dhcp snooping binding.
IOU1#sho ip dhcp snooping binding
MacAddress IpAddress Lease(sec) Type VLAN Interface
------------------ --------------- ---------- ------------- ---- --------------------
00:50:79:66:68:00 192.168.0.101 1992 dhcp-snooping 1 Ethernet0/0
Total number of bindings: 1
Иногда требуется внести статическую запись в базу данных привязок DHCP snooping. Для выполнения указанной операции используется команда ip dhcp snooping binding <mac-address> vlan <vid> <ip-address> interface <interface-id> expiry <seconds>. Ключевое слово expiry позволяет указать время, в течение которого создаваемая запись будет существовать. Максимальное значение, которое допускает опция expiry, составляет 4294967295 секунд, что примерно соответствует 136 годам.
Базу данных функции DHCP snooping можно сохранять в энергонезависимой памяти локально, либо на удалённых серверах.
IOU1(config)#ip dhcp snooping database ?
disk0: Database agent URL
disk1: Database agent URL
ftp: Database agent URL
http: Database agent URL
rcp: Database agent URL
scp: Database agent URL
tftp: Database agent URL
timeout Configure abort timeout interval
unix: Database agent URL
write-delay Configure delay timer for writes to URL
Пожалуй, здесь же можно ещё отметить, что сохранить на удалённых серверах или в энергонезависимой памяти можно не только базу данных функции DHCP snooping, но и саму базу DHCP привязок, то есть используемых в данный момент клиентами IP-адресов. Такое сохранение базы может потребоваться для того, чтобы не потерять указанную базу в момент перезагрузки устройства. Пример команды, сохраняющей базу привязок DHCP локальной, можно найти ниже.
ip dhcp database disk1:fox.txt
Однако файл будет создан не сразу после введения команды, но с определённой задержкой. По умолчанию такая задержка составляет 300 секунд. Удостовериться в этом можно с помощью команды sho run all, выводящей также значения параметров по умолчанию. В листинге ниже содержится та же команда, но вместе с параметрами по умолчанию.
ip dhcp database disk1:fox.txt write-delay 300 timeout 300
Содержимое сохранённого таким образом файла представлено ниже.
R1#more disk1:fox.txt
*time* Aug 24 2015 02:07 AM
*version* 4
!IP address Type Hardware address Lease expiration VRF
192.168.1.3 id 0063.6973.636f.2d63.6130.322e.3165.3663.2e30.3030.382d.4769.302f.30 Aug 25 2015 02:03 AM
!IP address Type Hardware address Interface-name
!IP address Interface-name Lease expiration Server IP address Hardware address Vrf
*end*
Ещё одной интересной опцией, о которой мы не можем не упомянуть здесь, является сообщение DHCP lease query, позволяющее запросить у DHCP-сервера информацию о выданных IP-адресах. Сообщение DHCP lease query может использоваться устройствами, выполняющими, например, функции DHCP ретрансляторов, в ситуации утери собственной базы активных привязок из-за аварийной перезагрузки или по иным причинам. Подобная информация может быть использована сетевым оборудованием, например, для выполнения защиты от IP spoofing атак, либо при необходимости выполнить аутентификацию клиента на основе его MAC-адреса сервисом SSG. Подробное изучение сообщения DHCP lease query далеко выходит за рамки данной статьи. Более подробную информацию об этом сообщении можно получить в RFC4388 и RFC6148.
Дополнительные возможности: импорт параметров
Иногда может возникнуть необходимость выдавать DHCP-клиентам параметры, которые в свою очередь также были получены динамически. Рассмотрим схему ниже.

Маршрутизатор R3 – оборудование провайдера, выполняет функции DHCP-сервера для подключённых клиентов. Маршрутизатор R2 – оборудование клиента, являющееся одновременно DHCP-клиентом в сети провайдера и DHCP-сервером в собственной сети, к которой подключён узел PC1. R3 выдаёт адреса из сети 192.168.1.0/24, R2 выдаёт адреса из сети 192.168.0.0/24. Задача состоит в том, чтобы передать определённые параметры, например, адрес DNS-сервера, от маршрутизатора R3 к узлу PC1. Поскольку адреса DNS-серверов передаются на R2 динамически, включить их в конфигурацию заранее не представляется возможным. Вместо этого нужно использовать опцию import all в настройках DHCP-пула. В приведённом ниже листинге содержится частичный конфиг маршрутизатора R3. Как мы видим, R3 отдаёт своим клиентам адрес DNS-сервера.
ip dhcp excluded-address 192.168.1.1 192.168.1.10
ip dhcp pool test
network 192.168.1.0 255.255.255.0
dns-server 8.8.8.8
interface GigabitEthernet0/0
ip address 192.168.1.1 255.255.255.0
Ниже приведён частичный конфиг маршрутизатора R2.
ip dhcp excluded-address 192.168.0.1 192.168.0.10
ip dhcp pool test2
import all
network 192.168.0.0 255.255.255.0
default-router 192.168.0.1
interface FastEthernet1/0
ip address 192.168.0.1 255.255.255.0
interface FastEthernet1/1
ip address dhcp
Как мы видим, маршрутизатор R2 не содержит информации о DNS-сервере, при этом узел PC1 соответствующую настройку получает.
PC1> sho ip
NAME : PC1[1]
IP/MASK : 192.168.0.12/24
GATEWAY : 192.168.0.1
DNS : 8.8.8.8
DHCP SERVER : 192.168.0.1
DHCP LEASE : 71323, 86400/43200/75600
MAC : 00:50:79:66:68:00
Здесь же хотелось бы обратить внимание читателей на одну вполне очевидную вещь – порядок действий. Чтобы импорт параметров был произведён успешно, необходимо, чтобы соответствующий DHCP-пул был уже полностью сконфигурирован до момента получения IP-параметров от оборудования провайдера.
Дополнительные возможности: поддержка VRF
В современных корпоративных сетях администраторы всё чаще прибегают к использованию VRF. Служба DHCP-сервера, реализованная в оборудовании Cisco, обладает поддержкой VRF. Рассмотрим ситуацию, когда к маршрутизатору подключаются клиенты, расположенные внутри определённой VRF, а также глобальные клиенты (не привязанные ни к какой VRF). Стоит напомнить, что VRF имеет локальную значимость, то есть никакие соседние устройства не знают о том, сконфигурированы ли какие-либо VRF на данном маршрутизаторе.
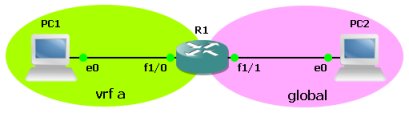
Итак, в нашем примере маршрутизатор R1 обладает двумя интерфейсами: FE 1/0 (принадлежит VRF a) и FE1/1 (принадлежит глобальной таблице маршрутизации). Подключение клиентов произведено так, как показано на схеме выше. В нашем примере мы будем использовать перекрывающиеся адреса сетей, например, 192.168.0.0/24. На оба интерфейса маршрутизатора мы назначим адрес 192.168.0.1/24. Исключим из раздачи адреса с первого по десятый включительно. Для проверки работоспособности схемы мы создадим два DHCP-пула, незначительно отличающиеся друг от друга. Клиенты, подключающиеся к глобальному пулу, будут получать адрес шлюза по умолчанию и адрес DNS-сервера 8.8.8.8. Клиенты, подключающиеся к интерфейсу, находящемуся в vrf a, не будут получать адрес шлюза по умолчанию, а адрес их DNS-сервера будет 8.8.4.4. Листинг ниже содержит основные параметры конфигурации маршрутизатора R1.
vrf definition a
rd 1:1
address-family ipv4
exit-address-family
ip dhcp excluded-address 192.168.0.1 192.168.0.10
ip dhcp excluded-address vrf a 192.168.0.1 192.168.0.10
ip dhcp pool global
network 192.168.0.0 255.255.255.0
default-router 192.168.0.1
dns-server 8.8.8.8
ip dhcp pool vrfa
vrf a
network 192.168.0.0 255.255.255.0
dns-server 8.8.4.4
interface FastEthernet1/0
vrf forwarding a
ip address 192.168.0.1 255.255.255.0
interface FastEthernet1/1
ip address 192.168.0.1 255.255.255.0
Просмотреть статистику использования пулов можно с помощью команды sho ip dhcp pool, отображающую также информацию о принадлежности пула определённой VRF.
R1#sho ip dhcp pool
Pool global :
Utilization mark (high/low) : 100 / 0
Subnet size (first/next) : 0 / 0
Total addresses : 254
Leased addresses : 1
Pending event : none
1 subnet is currently in the pool :
Current index IP address range Leased addresses
192.168.0.12 192.168.0.1 - 192.168.0.254 1
Pool vrfa :
Utilization mark (high/low) : 100 / 0
Subnet size (first/next) : 0 / 0
VRF name : a
Total addresses : 254
Leased addresses : 1
Pending event : none
1 subnet is currently in the pool :
Current index IP address range Leased addresses
192.168.0.12 192.168.0.1 - 192.168.0.254 1
Команда sho ip dhcp binding также отображает информацию о том, к какой VRF привязан клиент, получивший IP-адрес.
R1#sho ip dhcp binding
Bindings from all pools not associated with VRF:
IP address Client-ID/ Lease expiration Type
Hardware address/
User name
192.168.0.11 0100.5079.6668.01 Jan 09 2016 12:30 AM Automatic
Bindings from VRF pool a:
IP address Client-ID/ Lease expiration Type
Hardware address/
User name
192.168.0.11 0100.5079.6668.00 Jan 09 2016 12:30 AM Automatic
В заключение стоит отметить, что поддержка VRF и MPLS VPN присутствует также и для устройств, выполняющих функции DHCP ретранслятора. Желающие могут самостоятельно изучить следующие команды.
ip helper-address vrf
ip dhcp relay information option vpn
ip dhcp relay information option vpn-id
Дополнительные возможности: Voice VLAN
Необходимость в использовании Voice VLAN возникает в ситуации, когда требуется подключить компьютер через IP-телефон, при этом телефон и компьютер должны находиться в разных виртуальных сетях.
Получается такая цепочка из устройств.

Коммутатору и телефону нужно каким-то образом договориться о том, каким образом будут передаваться данные. Обычно на линке между коммутатором и телефоном передаётся тегированный трафик двух виртуальных сетей: голос и данные. На линке между компьютером и телефоном обычно передаётся не тегированный трафик соответствующей виртуальной сети.
В описанной выше ситуации интерфейс коммутатора находится в режиме доступа (access) даже несмотря на то, что трафик передаётся тегированный. Конечно, между коммутатором и телефоном можно поднять и полноценный транк, однако этого часто стараются избегать. Пример настройки голосовой виртуальной сети на интерфейсе коммутатора представлен ниже.
interface GigabitEthernet 1/0/1
switchport
switchport mode access
switchport access vlan 2
switchport voice vlan 3
Традиционно сигнализация номеров виртуальных сетей для голоса и данных производилась с помощью протоколов LLDP или CDP. Конечно, телефонный аппарат может быть и вручную сконфигурирован на использование соответствующих номеров виртуальных сетей. Однако, что делать в ситуации, когда по какой-либо причине использование CDP/LLDP невозможно, а производить настройки телефонов вручную очень не хочется?! На помощь придёт DHCP!
Итак, полная конфигурация интерфейса коммутатора, с которой мы будем работать, представлена ниже.
interface GigabitEthernet1/0/1
description DHCP_voice_VLAN_test
switchport access vlan 2
switchport mode access
switchport voice vlan 3
load-interval 30
no cdp enable
no lldp transmit
no lldp receive
spanning-tree portfast edge
В нашем распоряжении был IP-телефон Avaya модели 9620L. Телефоны данного вендора могут получать информацию о номере голосового VLAN с помощью опций №176 или №242. Мы сконфигурировали DHCP-пулы для обеих подсетей, включив в них обе упомянутые опции. Сеть с данными: VLAN2 и подсеть 192.168.2.0/24. Голосовая сеть: VLAN3 и подсеть 192.168.3.0/24.
fox_switch#sho run | s pool
ip dhcp pool voice
network 192.168.3.0 255.255.255.0
default-router 192.168.3.1
dns-server 8.8.8.8
option 242 ascii "L2QVLAN=3,L2Q=1"
option 176 ascii "L2QVLAN=3,L2Q=1"
ip dhcp pool data
network 192.168.2.0 255.255.255.0
default-router 192.168.2.1
dns-server 8.8.8.8
option 242 ascii "L2QVLAN=3,L2Q=1"
option 176 ascii "L2QVLAN=3,L2Q=1"
С помощью L2Q=1 включается использование меток IEEE 802.1Q, тогда как параметр L2QVLAN позволяет задать номер виртуальной сети для голоса.
После того, как телефон полностью загрузился, он использует адрес из голосовой виртуальной сети, данные же с ПК помещаются в VLAN 2.
fox_switch#sho ip dhcp binding
Bindings from all pools not associated with VRF:
IP address Client-ID/ Lease expiration Type State Interface
Hardware address/
User name
192.168.3.6 3cb1.5b4b.9cc7 Jan 02 2000 06:31 AM Automatic Active Vlan3
Но что же произошло за сценой? Опишем весь процесс чуть подробнее.
- Телефон загружается и передаёт данные без тегирования, то есть в data-vlan.
- С помощью DHCP телефон получает основные сетевые параметры: IP-адрес, маску, шлюз, адрес DNS-сервера и так далее. Среди параметров передаётся также номер голосовой виртуальной сети.
- Телефон освобождает полученный ранее адрес, переинициализирует стек и получает IP-адрес уже в голосовом VLAN. В данный момент используются уже тегированные Ethernet-кадры.
Именно потому, что на третьем шаге происходит освобождение арендованного ранее адреса, мы видим лишь один выданный с помощью DHCP IP-адрес. Однако запись в ARP-таблице ещё будет сохраняться некоторое время.
fox_switch#sho ip arp
Protocol Address Age (min) Hardware Addr Type Interface
Internet 192.168.2.1 - 9c57.adb0.34c4 ARPA Vlan2
Internet 192.168.2.4 0 3cb1.5b4b.9cc7 ARPA Vlan2
Internet 192.168.3.1 - 9c57.adb0.34c5 ARPA Vlan3
Internet 192.168.3.6 0 3cb1.5b4b.9cc7 ARPA Vlan3
Также косвенным подтверждением наших слов является наличие записи о MAC-адресе телефона в обоих виртуальных сетях в таблице коммутации в течение времени Aging Time. Коммутаторы Cisco Catalyst по умолчанию сохраняют такую запись в течение пяти минут.
fox_switch#sho mac add int gi1/0/1
Mac Address Table
-------------------------------------------
Vlan Mac Address Type Ports
---- ----------- -------- -----
2 3cb1.5b4b.9cc7 DYNAMIC Gi1/0/1
3 3cb1.5b4b.9cc7 DYNAMIC Gi1/0/1
Total Mac Addresses for this criterion: 2
Мы решили предоставить лог работы DHCP-сервера, встроенного в наш коммутатор, в виде отдельного файла.
Такое поведение телефона необходимо обязательно учитывать, если проектируется какая-либо защита коммутатора на втором уровне, например, port-security.
DHCP и туннельные интерфейсы
Протокол DHCP может использоваться не только для назначения IP-адресов при Ethernet подключениях, но и в случае использования туннелей. Рассмотрим для начала туннели типа точка-точка на базе протоколов IPIP или GRE. Схема сети представлена ниже. Маршрутизатор R1 выполняет функции DHCP-сервера, а R3 – DHCP-клиента.

Со стороны DHCP-сервера или релея конфигурация стандартная.
R1#sho run | sec dhcp
ip dhcp pool fox
network 10.0.0.0 255.255.255.252
default-router 10.0.0.1
dns-server 8.8.8.8
R1#sho run int tu 0
Building configuration...
Current configuration : 145 bytes
!
interface Tunnel0
ip address 10.0.0.1 255.255.255.0
tunnel source GigabitEthernet0/0
tunnel mode ipip
tunnel destination 192.168.23.3
end
Настройки клиентской части также весьма просты.
R3#sho run int tunnel 0
Building configuration...
Current configuration : 127 bytes
!
interface Tunnel0
ip address dhcp
tunnel source GigabitEthernet1/0
tunnel mode ipip
tunnel destination 192.168.12.1
end
Перехват трафика внутри IPIP туннеля показывает вполне стандартные сообщения протокола DHCP. Для туннелей на базе GRE ситуация аналогичная.
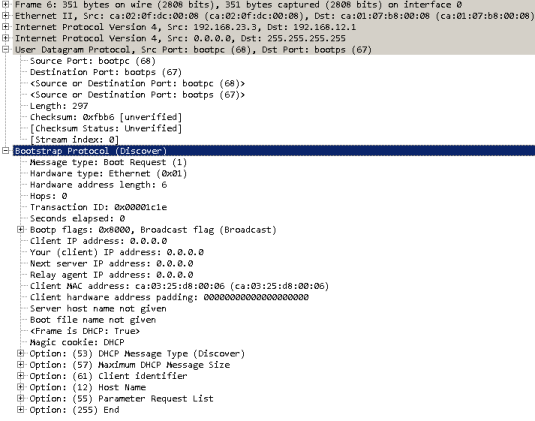
Немного сложнее обстоит дело с туннелями на базе DMVPN. Если выполнить такую же настройку DHCP для интерфейсов, как и при обычном GRE/IPIP, то через туннель от клиента будут передаваться сообщения DHCP Discover, но ничего не будет возвращаться назад.
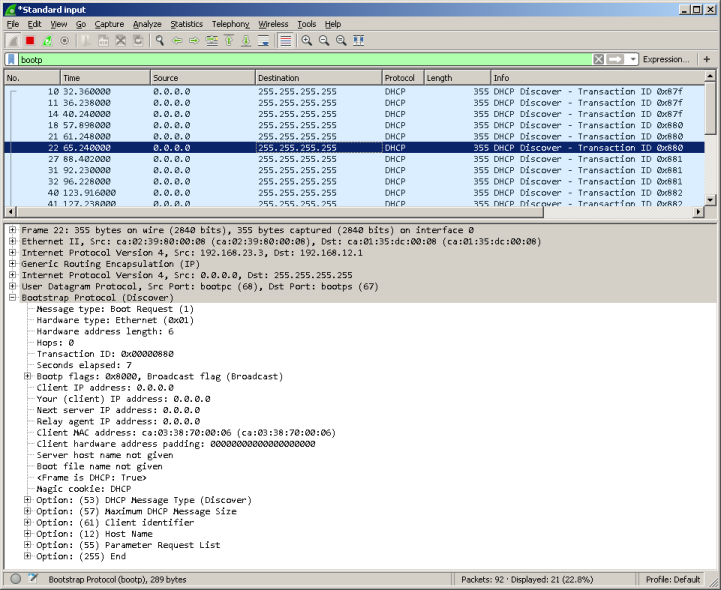
Со стороны DHCP-сервера появляются следующие отладочные сообщения (deb ip dhcp events). Маршрутизатор R1 выполняет функции hub, а R3 – spoke для DMVPN в топологии, представленной в начале данного раздела.
R1#
*Apr 17 18:10:00.059: DHCPD: Sending notification of DISCOVER:
*Apr 17 18:10:00.059: DHCPD: htype 1 chaddr ca03.3870.0006
*Apr 17 18:10:00.063: DHCPD: circuit id 00000000
*Apr 17 18:10:00.063: DHCPD: Seeing if there is an internally specified pool class:
*Apr 17 18:10:00.063: DHCPD: htype 1 chaddr ca03.3870.0006
*Apr 17 18:10:00.063: DHCPD: circuit id 00000000
*Apr 17 18:10:00.063: DHCPD: Found previous server binding
С точки зрения маршрутизатора R1, клиент получил адрес.
R1#sho ip dhcp binding
Bindings from all pools not associated with VRF:
IP address Client-ID/ Lease expiration Type
Hardware address/
User name
10.0.0.2 0063.6973.636f.2d63. Apr 17 2017 06:56 PM Automatic
6130.332e.3338.3730.
2e30.3030.362d.5475.
30
Однако, очевидно, что всё не совсем так с точки зрения клиента.
R3#sho ip int bri | i up
GigabitEthernet1/0 192.168.23.3 YES manual up up
Tunnel0 unassigned YES DHCP up up
Проблема кроется в том, что клиент выставляет флаг Broadcast в своих сообщения DHCP Discover. Для решения проблемы необходимо выполнить два действия: заставить клиента снимать флаг Broadcast (интерфейсная команда ip dhcp client broadcast-flag clear), а также заставить сервер отправлять все сообщения клиенту с помощью unicast сообщений (команда ip dhcp support tunnel unicast глобального режима).
Действие команды, снимающей флаг Broadcast, явно видно в сообщениях DHCP Discover.
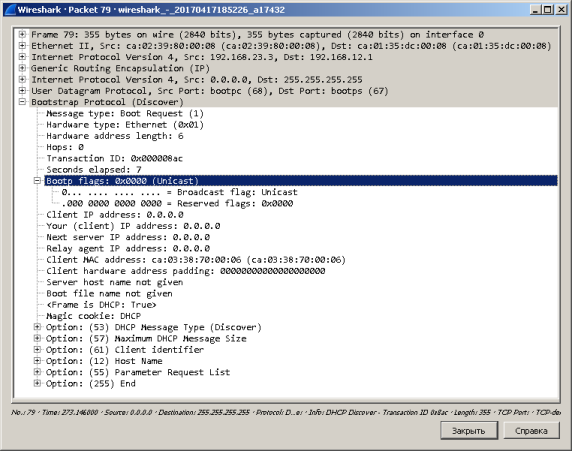
Действие команды со стороны сервера, включающей поддержку отправки DHCP-сообщений в режиме unicast, тоже не заставит себя долго ждать: клиент получит адрес сразу после первого присланного запроса.
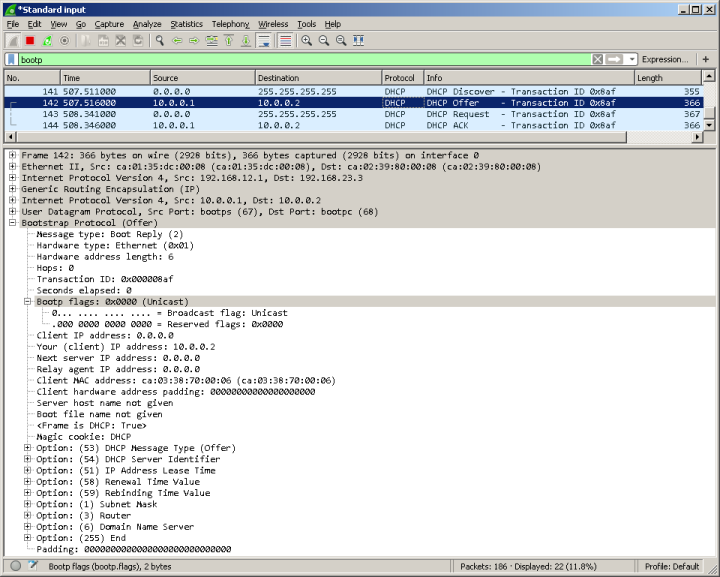
Таким образом, клиент может получать динамически адрес не только для своего NBMA-интерфейса, но и для туннельного также.
На это мы завершаем данный раздел и переходим к рассмотрению связи протокола DHCP и процессов маршрутизации.
DHCP и маршрутизация
В данном разделе мы решили затронуть вопросы, связанные с взаимодействием протокола DHCP и процессами построения таблицы маршрутизации. Начать мы решили с протоколов динамической маршрутизации (IGP).
Допустим, перед нами стоит задача в общем виде: требуется установить EIGRP соседство с устройствами, подключёнными к интерфейсуGi0/0 маршрутизатора R2, IP-адрес на котором конфигурируется динамически и диапазон адресов не известен.

В этом случае в настройках процесса маршрутизации EIGRP нужно выполнить три команды: отключить EIGRP на всех интерфейсах (passive-interface default), включить маршрутизацию для всех сетей (network 0.0.0.0), включить поддержку интерфейса Gi0/0 в EIGRP (no passive-interface GigabitEthernet0/0). Конфигурация маршрутизатора R1 типична, поэтому мы не приводим её здесь. Основные конфигурационные команды, введённые на маршрутизаторе R2 представлены ниже.
interface GigabitEthernet0/0
ip address dhcp
!
router eigrp 1
network 0.0.0.0
passive-interface default
no passive-interface GigabitEthernet0/0
После этого EIGRP-соседство с маршрутизатором R1 успешно устанавливается.
R2# sho ip eigrp interfaces
EIGRP-IPv4 Interfaces for AS(1)
Xmit Queue PeerQ Mean Pacing Time Multicast Pending
Interface Peers Un/Reliable Un/Reliable SRTT Un/Reliable Flow Timer Routes
Gi0/0 1 0/0 0/0 24 0/0 64 0
R2#sho ip eigrp neighbors
EIGRP-IPv4 Neighbors for AS(1)
H Address Interface Hold Uptime SRTT RTO Q Seq
(sec) (ms) Cnt Num
0 192.168.0.1 Gi0/0 13 00:05:10 24 144 0 3
Конфигурация протокола RIP аналогична и приведена ниже.
router rip
version 2
passive-interface default
no passive-interface GigabitEthernet0/0
network 0.0.0.0
no auto-summary
Протокол динамической маршрутизации OSPF может быть настроен аналогично EIGRP и RIP.
router ospf 1
passive-interface default
no passive-interface GigabitEthernet0/0
network 0.0.0.0 255.255.255.255 area 0
Однако из приведённого выше примера конфигурации протокола OSPF вытекает очевидное ограничение: если интерфейсов, на которых адрес назначается динамически, два или более, они все должны будут принадлежать одной зоне. К счастью для OSPF существует интерфейсная команда, позволяющая включить данный протокол на конкретном интерфейсе без указания IP-адреса, но с указанием номера зоны. Пример такой конфигурации представлен ниже, в нём все доступные интерфейсы добавляются в зону №1, тогда как Gi0/0 принадлежит магистральной зоне.
interface GigabitEthernet0/0
ip address dhcp
ip ospf 1 area 0
!
router ospf 1
router-id 2.2.2.2
network 0.0.0.0 255.255.255.255 area 1
Протокол динамической маршрутизации OSPF позволяет выяснить, какие интерфейсы и почему участвуют в маршрутизации, а также каким зонам они принадлежат. Для вывода указанной информации предназначена команда sho ip proto, пример работы которой представлен ниже.
R2#sho ip protocols
*** IP Routing is NSF aware ***
Routing Protocol is "ospf 1"
Outgoing update filter list for all interfaces is not set
Incoming update filter list for all interfaces is not set
Router ID 2.2.2.2
It is an area border and autonomous system boundary router
Redistributing External Routes from,
connected, includes subnets in redistribution
Number of areas in this router is 2. 2 normal 0 stub 0 nssa
Maximum path: 4
Routing for Networks:
0.0.0.0 255.255.255.255 area 1
Routing on Interfaces Configured Explicitly (Area 0):
GigabitEthernet0/0
Routing Information Sources:
Gateway Distance Last Update
1.1.1.1 110 00:00:05
Distance: (default is 110)
Ещё одним локальным протоколом динамической маршрутизации, популярным в сетях крупных операторов связи, является ISIS. И хотя ISIS редок в корпоративных сетях, мы решили упомянуть и его, благо настройка данного IGP для работы с DHCP чрезвычайно проста и похожа на настройку OSPF. ISIS не поддерживает команду network для указания интерфейсов, на которых данный протокол будет работать. Вместо этого должна использоваться лишь интерфейсная команда. Пример настройки ISIS представлен ниже.
interface GigabitEthernet0/0
ip address dhcp
ip router isis
!
router isis
net 49.0001.0000.0000.0002.00
Также мы решили представить нашим читателям вывод нескольких диагностических команд.
R2#sho isis neighbors
System Id Type Interface IP Address State Holdtime Circuit Id
R1 L1 Gi0/0 192.168.0.1 UP 29 R2.01
R1 L2 Gi0/0 192.168.0.1 UP 23 R2.01
R2#sho ip ro
Codes: L - local, C - connected, S - static, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2
i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default, U - per-user static route
o - ODR, P - periodic downloaded static route, H - NHRP, l - LISP
+ - replicated route, % - next hop override
Gateway of last resort is not set
1.0.0.0/32 is subnetted, 1 subnets
i L2 1.1.1.1 [115/10] via 192.168.0.1, 00:07:05, GigabitEthernet0/0
2.0.0.0/32 is subnetted, 1 subnets
C 2.2.2.2 is directly connected, Loopback0
192.168.0.0/24 is variably subnetted, 2 subnets, 2 masks
C 192.168.0.0/24 is directly connected, GigabitEthernet0/0
L 192.168.0.2/32 is directly connected, GigabitEthernet0/0
R2#sho ip protocols
*** IP Routing is NSF aware ***
Routing Protocol is "isis"
Outgoing update filter list for all interfaces is not set
Incoming update filter list for all interfaces is not set
Redistributing: connected, isis
Address Summarization:
None
Maximum path: 4
Routing for Networks:
GigabitEthernet0/0
Routing Information Sources:
Gateway Distance Last Update
192.168.0.1 115 00:06:56
Distance: (default is 115)
С динамической маршрутизацией, будем считать, разобрались, однако остаются не менее интересные вопросы, связанные со статической маршрутизацией.
Во-первых, может потребоваться передать клиенту по протоколу DHCP не только маршрут по умолчанию, но и другие статические маршруты. Маршрут по умолчанию (опция №3) можно передать с помощью команды default-router в режиме конфигурации DHCP пула. Статические маршруты передаются с помощью опции №33, запрашиваемой клиентом. Мы собрали небольшую схему, чтобы проиллюстрировать работу данных опций.
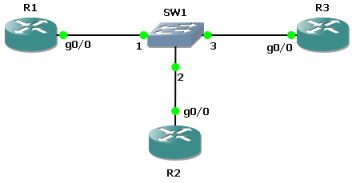
Маршрутизаторы R1 и R2 имеют статическую конфигурацию интерфейсов. На интерфейсах Gi0/0 настроены адреса 192.168.0.1/24 и 192.168.0.2/24. Также на этих маршрутизаторах настроены интерфейсы loopback 0 с адресами 1.1.1.1/32 и 2.2.2.2/32. Маршрутизатор R3 получает IP-параметры динамически с помощью интерфейсной команды ip addr dhcp. Настройки DHCP на маршрутизаторе R1 представлены ниже. С помощью опции №33 передаются статические маршруты.
ip dhcp excluded-address 192.168.0.1 192.168.0.100
ip dhcp pool foxnetwork
network 192.168.0.0 255.255.255.0
dns-server 8.8.8.8
default-router 192.168.0.1
option 33 ip 2.2.2.2 192.168.0.2
Естественно, мы не могли не убедиться в том, что маршрутизатор R3 успешно получил все необходимые параметры.
R3#sho ip int bri
Interface IP-Address OK? Method Status Protocol
Ethernet0/0 unassigned YES unset administratively down down
GigabitEthernet0/0 192.168.0.101 YES DHCP up up
R3#sho ip ro
Codes: L - local, C - connected, S - static, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2
i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default, U - per-user static route
o - ODR, P - periodic downloaded static route, H - NHRP, l - LISP
+ - replicated route, % - next hop override
Gateway of last resort is 192.168.0.1 to network 0.0.0.0
S* 0.0.0.0/0 [254/0] via 192.168.0.1
2.0.0.0/32 is subnetted, 1 subnets
S 2.2.2.2 [254/0] via 192.168.0.2
192.168.0.0/24 is variably subnetted, 2 subnets, 2 masks
C 192.168.0.0/24 is directly connected, GigabitEthernet0/0
L 192.168.0.101/32 is directly connected, GigabitEthernet0/0
R3#ping 2.2.2.2
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 2.2.2.2, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 4/8/16 ms
Весь обмен трафиком мы сохранили в дампе foxnetwork_8.pcapng.
Использование опции №33 чрезвычайно простое, однако с данной опцией невозможно передать маршрут с маской отличной от /32. Выполнить передачу маршрута с произвольной маской DHCP клиенту, расположенному на маршрутизаторе Cisco, можно с помощью опции №121, правда, правило её формирования чуть сложнее. Все числа записываются в шестнадцатеричном виде. Первый октет содержит длину маски. Дальше содержатся значащие октеты адреса сети назначения, после которых указывается адрес следующего маршрутизатора. Если требуется передать несколько маршрутов одновременно, все они записываются последовательно друг за другом без пробелов. Разберём сказанное выше на примере. Допустим, мы используем предыдущую схему сети и хотим передать следующие маршруты: 1.1.1.1/32 через 192.168.0.1 и 2.2.2.0/23 через 192.168.0.2. Первый маршрут содержит четыре значащих октета сети, второй – три. Поэтому записи указанных маршрутов в шестнадцатеричном виде будут такими: 2001010101C0A80001 и 17020202C0A80002, где 20 и 17 – длины масок в шестнадцатеричном виде, 01010101 и 020202 – шестнадцатеричная запись значащих октетов адреса сети, а C0A80001 и C0A80002 – адреса маршрутизаторов. Пример обновлённой конфигурации DHCP пула маршрутизатора R1 представлен ниже.
ip dhcp pool foxnetwork
network 192.168.0.0 255.255.255.0
dns-server 8.8.8.8
option 121 hex 2001.0101.01c0.a800.0117.0202.02c0.a800.02
Однако указанных команд недостаточно. По умолчанию DHCP-клиент на базе Cisco IOS не запрашивает у сервера опцию №121. Заставить клиента запрашивать данную опцию можно с помощью интерфейсной команды ip dhcp client request classless-static-route, выполняемой на клиенте. Убедимся в работоспособности представленной конфигурации.
R3#conf t
Enter configuration commands, one per line. End with CNTL/Z.
R3(config)#int gi0/0
R3(config-if)# ip dhcp client request classless-static-route
R3(config-if)#ip add dhcp
R3(config-if)#^Z
R3#
*Aug 16 04:23:03.179: %SYS-5-CONFIG_I: Configured from console by console
*Aug 16 04:23:04.467: %DHCP-6-ADDRESS_ASSIGN: Interface GigabitEthernet0/0 assigned DHCP address 192.168.0.106, mask 255.255.255.0, hostname R3
R3#sho ip int bri
Interface IP-Address OK? Method Status Protocol
Ethernet0/0 unassigned YES unset administratively down down
GigabitEthernet0/0 192.168.0.106 YES DHCP up up
R3#sho ip ro
Codes: L - local, C - connected, S - static, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2
i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default, U - per-user static route
o - ODR, P - periodic downloaded static route, H - NHRP, l - LISP
+ - replicated route, % - next hop override
Gateway of last resort is not set
1.0.0.0/32 is subnetted, 1 subnets
S 1.1.1.1 [254/0] via 192.168.0.1
2.0.0.0/23 is subnetted, 1 subnets
S 2.2.2.0 [254/0] via 192.168.0.2
192.168.0.0/24 is variably subnetted, 2 subnets, 2 masks
C 192.168.0.0/24 is directly connected, GigabitEthernet0/0
L 192.168.0.106/32 is directly connected, GigabitEthernet0/0
R3#ping 1.1.1.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 1.1.1.1, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 16/17/20 ms
R3#ping 2.2.2.2
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 2.2.2.2, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 8/15/20 ms
R3#
Перехват процесса обмена трафиком между тремя маршрутизаторами представлен в файле foxnetwork_9.pcapng.
Передача статических маршрутов DHCP клиентам, выполняющихся на других операционных системах может производится с помощью других опций, однако в любом случае любая опция – всего лишь hex-строка, то есть DHCP сервер на базе маршрутизаторов Cisco может быть сконфигурирован на передачу маршрутной информации клиентам и на других операционных системах тоже.
Также стоит отметить, что получаемые по DHCP маршруты, могут быть переданы в любой протокол динамической маршрутизации с помощью команды redistribute static (или redistribute static subnets при использовании OSPF).
По умолчанию DHCP клиент на базе Cisco IOS запрашивает целый набор опций, в число которых, например, входит маршрут по умолчанию (опция №3). Отучить маршрутизатор от запроса некоторых опций можно с помощью соответствующих интерфейсных команд.
R3(config-if)#no ip dhcp client request ?
classless-static-route Classless static route (121)
dns-nameserver DNS nameserver (6)
domain-name Domain name (15)
netbios-nameserver NETBIOS nameserver (44)
router Default router option (3)
sip-server-address SIP server address (120)
static-route Static route option (33)
tftp-server-address TFTP server address (150)
vendor-identifying-specific Vendor identifying specific info (125)
vendor-specific Vendor specific option (43)
<cr>
На картинках ниже показаны сообщения DHCP discover и DHCP offer от маршрутизаторов R3 и R1, на котором в режиме конфигурации DHCP пула была введена команда default-router. На интерфейсе Gi0/0 маршрутизатора R3 мы предварительно выполнили команду no ip dhcp client request router.
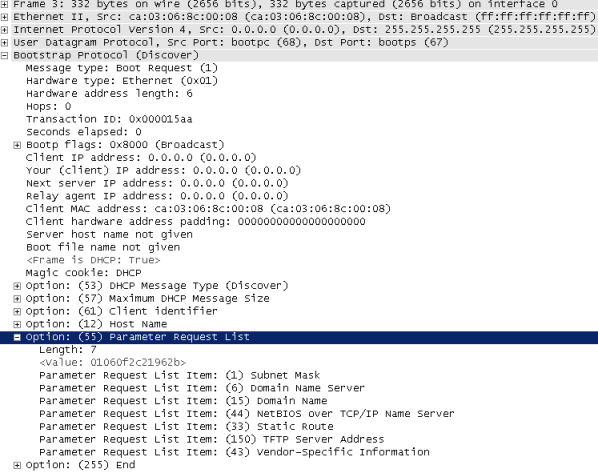
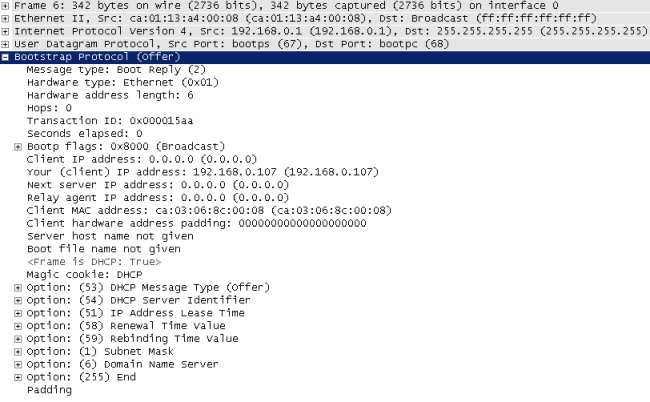
Как видно из двух представленных выше DHCP сообщений, маршрутизатор R3 не запрашивает опцию №3, а R1 не отправляет её клиенту. DHCP сообщения, которыми обменивались маршрутизаторы R1 и R3 представлены в файле foxnetwork_10.pcapng.
Наш внимательный читатель уже, наверняка, обратил внимание на то, с каким значением административной дистанции в таблице маршрутизации появлялся маршрут по умолчанию, получаемый по протоколу DHCP – 254. Такое значение AD говорит о том, что практически любой статически сконфигурированный маршрут или маршрут, полученный с помощью любого IGP или даже BGP, окажется приоритетнее того, который был получен с помощью DHCP. Изменить дистанцию маршрута по умолчанию, получаемого с помощью DHCP можно командой ip dhcp-client default-router distance из режима глобальной конфигурации. Данная команда влияет лишь на вновь получаемый маршрут, оставляя неизменным тот, что уже находится в таблице маршрутизации. Если же маршрутизатор динамически получает маршрут по умолчанию через два или большее количество интерфейсов, то изменить предпочтения можно с помощью интерфейсной команды ip dhcp client default-router distance, влияющей только на маршрут по умолчанию, получаемый через определённый интерфейс. Проиллюстрируем всё вышесказанное на примере небольшой сети. Маршрутизаторы R1 и R3 настроены как DHCP серверы, тогда как R2 выполняет функции DHCP клиента.
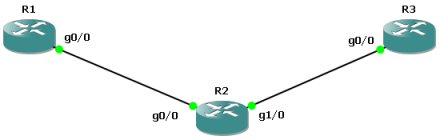
На маршрутизаторе R1 введена следующая конфигурация.
interface GigabitEthernet0/0
ip address 192.168.12.1 255.255.255.0
ip dhcp pool test
network 192.168.12.0 255.255.255.0
default-router 192.168.12.1
Конфигурация R3 практически идентична.
interface GigabitEthernet0/0
ip address 192.168.23.3 255.255.255.0
ip dhcp pool test
network 192.168.23.0 255.255.255.0
default-router 192.168.23.3
Рассмотрим процесс получения IP-параметров маршрутизатором R2, во время которого мы сначала получаем IP-адрес от маршрутизатора R1, затем меняем административную дистанцию глобально, повторно запрашиваем IP-параметры, меняем административную дистанцию для интерфейса Gi1/0 и запрашиваем IP-адрес и маршрут по умолчанию у маршрутизатора R3.
R2#sho ip int bri
Interface IP-Address OK? Method Status Protocol
Ethernet0/0 unassigned YES unset administratively down down
GigabitEthernet0/0 unassigned YES unset up up
GigabitEthernet1/0 unassigned YES unset up up
R2#conf t
Enter configuration commands, one per line. End with CNTL/Z.
R2(config)#int gi0/0
R2(config-if)#ip add dh
*Aug 16 08:05:21.255: %DHCP-6-ADDRESS_ASSIGN: Interface GigabitEthernet0/0 assigned DHCP address 192.168.12.6, mask 255.255.255.0, hostname R2
R2(config-if)#do sho ip int bri
Interface IP-Address OK? Method Status Protocol
Ethernet0/0 unassigned YES unset administratively down down
GigabitEthernet0/0 192.168.12.6 YES DHCP up up
GigabitEthernet1/0 unassigned YES unset up up
R2(config-if)#do sho ip ro
Codes: L - local, C - connected, S - static, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2
i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default, U - per-user static route
o - ODR, P - periodic downloaded static route, H - NHRP, l - LISP
+ - replicated route, % - next hop override
Gateway of last resort is 192.168.12.1 to network 0.0.0.0
S* 0.0.0.0/0 [254/0] via 192.168.12.1
192.168.12.0/24 is variably subnetted, 2 subnets, 2 masks
C 192.168.12.0/24 is directly connected, GigabitEthernet0/0
L 192.168.12.6/32 is directly connected, GigabitEthernet0/0
R2(config-if)#exi
R2(config)#ip dhcp-client default-router distance 10
R2(config)#do sho ip ro
Codes: L - local, C - connected, S - static, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2
i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default, U - per-user static route
o - ODR, P - periodic downloaded static route, H - NHRP, l - LISP
+ - replicated route, % - next hop override
Gateway of last resort is 192.168.12.1 to network 0.0.0.0
S* 0.0.0.0/0 [254/0] via 192.168.12.1
192.168.12.0/24 is variably subnetted, 2 subnets, 2 masks
C 192.168.12.0/24 is directly connected, GigabitEthernet0/0
L 192.168.12.6/32 is directly connected, GigabitEthernet0/0
R2(config)#int gi0/0
R2(config-if)#no ip add dh
R2(config-if)#ip add dh
*Aug 16 08:06:23.807: %DHCP-6-ADDRESS_ASSIGN: Interface GigabitEthernet0/0 assigned DHCP address 192.168.12.7, mask 255.255.255.0, hostname R2
R2(config-if)#do sho ip int bri
Interface IP-Address OK? Method Status Protocol
Ethernet0/0 unassigned YES unset administratively down down
GigabitEthernet0/0 192.168.12.7 YES DHCP up up
GigabitEthernet1/0 unassigned YES unset up up
R2(config-if)#do sho ip ro
Codes: L - local, C - connected, S - static, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2
i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default, U - per-user static route
o - ODR, P - periodic downloaded static route, H - NHRP, l - LISP
+ - replicated route, % - next hop override
Gateway of last resort is 192.168.12.1 to network 0.0.0.0
S* 0.0.0.0/0 [10/0] via 192.168.12.1
192.168.12.0/24 is variably subnetted, 2 subnets, 2 masks
C 192.168.12.0/24 is directly connected, GigabitEthernet0/0
L 192.168.12.7/32 is directly connected, GigabitEthernet0/0
R2(config-if)#int gi1/0
R2(config-if)#ip dhcp client default-router distance 5
R2(config-if)#ip add dh
*Aug 16 08:07:00.471: %DHCP-6-ADDRESS_ASSIGN: Interface GigabitEthernet1/0 assigned DHCP address 192.168.23.1, mask 255.255.255.0, hostname R2
R2(config-if)#do sho ip int bri
Interface IP-Address OK? Method Status Protocol
Ethernet0/0 unassigned YES unset administratively down down
GigabitEthernet0/0 192.168.12.7 YES DHCP up up
GigabitEthernet1/0 192.168.23.1 YES DHCP up up
R2(config-if)#do sho ip ro
Codes: L - local, C - connected, S - static, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2
i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default, U - per-user static route
o - ODR, P - periodic downloaded static route, H - NHRP, l - LISP
+ - replicated route, % - next hop override
Gateway of last resort is 192.168.23.3 to network 0.0.0.0
S* 0.0.0.0/0 [5/0] via 192.168.23.3
192.168.12.0/24 is variably subnetted, 2 subnets, 2 masks
C 192.168.12.0/24 is directly connected, GigabitEthernet0/0
L 192.168.12.7/32 is directly connected, GigabitEthernet0/0
192.168.23.0/24 is variably subnetted, 2 subnets, 2 masks
C 192.168.23.0/24 is directly connected, GigabitEthernet1/0
L 192.168.23.1/32 is directly connected, GigabitEthernet1/0
Ещё, пожалуй, стоит отметить, что администратор может вручную удалить или восстановить те или иные маршруты, полученные при помощи DHCP, из таблицы маршрутизации. Восстановить, естественно, можно лишь те маршруты, которые DHCP сервер реально объявлял в сообщении DHCP offer. Правда, восстановление происходит с административной дистанцией обычного статического маршрута, если не указать значение AD дополнительно. Также введённая команда ip route попадёт в текущую и/или загрузочную конфигурацию маршрутизатора.
Подключение к провайдеру с использованием динамически конфигурируемого IP-адреса позволяет обеспечить доступ к глобальной сети узлам, расположенным в пользовательской сети, с помощью NAT/PAT. Рассмотрим сеть, представленную на схеме ниже.

Маршрутизатор R1 принадлежит провайдеру и выполняет функции DHCP сервера для сети 192.168.0.0/24. Пользовательский маршрутизатор R2 интерфейсом Gi0/0 подключён к провайдеру, а интерфейсом Gi1/0 – к локальной сети пользователя 192.168.1.0/24. Естественно, маршрутизатор R1 не имеет маршрутов к внутренней клиентской сети. Настройка маршрутизатора R1 чрезвычайно простая и представлена ниже.
ip dhcp pool foxnetwork
network 192.168.0.0 255.255.255.0
default-router 192.168.0.1
interface Loopback0
ip address 1.1.1.1 255.255.255.0
interface GigabitEthernet0/0
ip address 192.168.0.1 255.255.255.0
Конфигурация узла PC1 также предельно проста.
PC1> sho ip
NAME : PC1[1]
IP/MASK : 192.168.1.2/24
GATEWAY : 192.168.1.1
DNS :
MAC : 00:50:79:66:68:00
LPORT : 10003
RHOST:PORT : 192.168.56.1:10002
MTU: : 1500
Единственное, что осталось, - настроить маршрутизатор R2. Первое, с чего мы начнём, - создадим список доступа, отбирающий IP-адреса, для которых будет производиться трансляция. Затем нужно указать IP-адреса на интерфейсах Gi0/0 и Gi1/0, указать внутренний и внешний интерфейс для NAT, а также создать саму трансляцию. При создании трансляции требуется указывать ключевое слово overload, заставляющее маршрутизатор выполнять PAT трансляцию. Пример конфигурации маршрутизатора R2 представлен ниже.
interface GigabitEthernet0/0
ip address dhcp
ip nat outside
ip virtual-reassembly in
interface GigabitEthernet1/0
ip address 192.168.1.1 255.255.255.0
ip nat inside
ip virtual-reassembly in
ip nat inside source list PAT interface GigabitEthernet0/0 overload
ip access-list extended PAT
permit ip 192.168.1.0 0.0.0.255 any
Убедимся в корректности конфигурации с помощью узла PC1.
PC1> ping 1.1.1.1
84 bytes from 1.1.1.1 icmp_seq=1 ttl=254 time=29.002 ms
84 bytes from 1.1.1.1 icmp_seq=2 ttl=254 time=29.002 ms
84 bytes from 1.1.1.1 icmp_seq=3 ttl=254 time=29.002 ms
84 bytes from 1.1.1.1 icmp_seq=4 ttl=254 time=29.002 ms
84 bytes from 1.1.1.1 icmp_seq=5 ttl=254 time=29.002 ms
Проверим то же самое, включив вывод отладочной информации на маршрутизаторе R1. Естественно, мы не рекомендуем включать отладку в высоконагруженных сетях.
R1#deb ip icmp
ICMP packet debugging is on
R1#
*Aug 16 19:58:21.931: ICMP: echo reply sent, src 1.1.1.1, dst 192.168.0.2, topology BASE, dscp 0 topoid 0
*Aug 16 19:58:22.959: ICMP: echo reply sent, src 1.1.1.1, dst 192.168.0.2, topology BASE, dscp 0 topoid 0
*Aug 16 19:58:23.975: ICMP: echo reply sent, src 1.1.1.1, dst 192.168.0.2, topology BASE, dscp 0 topoid 0
*Aug 16 19:58:25.003: ICMP: echo reply sent, src 1.1.1.1, dst 192.168.0.2, topology BASE, dscp 0 topoid 0
*Aug 16 19:58:26.035: ICMP: echo reply sent, src 1.1.1.1, dst 192.168.0.2, topology BASE, dscp 0 topoid 0
При проверке на маршрутизаторе R2 создаются следующие трансляции.
R2#sho ip nat translations
Pro Inside global Inside local Outside local Outside global
icmp 192.168.0.2:16835 192.168.1.2:16835 1.1.1.1:16835 1.1.1.1:16835
icmp 192.168.0.2:17091 192.168.1.2:17091 1.1.1.1:17091 1.1.1.1:17091
icmp 192.168.0.2:17347 192.168.1.2:17347 1.1.1.1:17347 1.1.1.1:17347
icmp 192.168.0.2:17859 192.168.1.2:17859 1.1.1.1:17859 1.1.1.1:17859
icmp 192.168.0.2:18115 192.168.1.2:18115 1.1.1.1:18115 1.1.1.1:18115
Конечно же, убедиться в корректности выполненных настроек можно было с помощью сетевого анализатора Wireshark, анализируя проходящие пакеты.
На этом мы завершаем раздел, описывающий взаимное влияние протокола DHCP и маршрутизации и переходим к подведению итогов.
Заключение
В данной статье мы попытались достаточно детально описать возможности и примеры использования протокола DHCP. Мы не ставили перед собой цели рассмотреть абсолютно все возможности всех реализаций и платформ, вместо этого мы решили познакомить наших читателей с наиболее часто используемыми опциями и функциями. Так, например, мы умышленно опустили вопросы, связанные с использованием DHCP на ATM-интерфейсах, так как наивно полагаем, что время повсеместного внедрения ATM уже давно позади.
Несмотря на то, что практически все конфиги приведены для оборудования компании Cisco, мы надеемся, что администраторы, в чьём ведении находится оборудование других производителей, смогут также найти в этой статье много интересного.
IPv6 в Cisco или будущее уже рядом
![]()
Туннелирование в среде IPv4 и IPv6
Виртуальные процессы маршрутизации (VRF)
Введение
Протокол IPv6 является наследником повсеместно используемого сегодня протокола IP четвёртой версии, IPv4, и естественно, наследует большую часть логики работы этого протокола. Так, например, заголовки пакетов в IPv4 и IPv6 очень похожи, используется та же логика пересылки пакетов – маршрутизация на основе адреса получателя, контроль времени нахождения пакета в сети с помощью TTL и так далее. Однако, есть и существенные отличия: кроме изменения длины самого IP-адреса, произошёл отказ от использования широковещания в любой форме, включая направленное (Broadcast, Directed broadcast). Вместо него теперь используются групповые рассылки (multicast). Также исчез ARP-протокол, функции которого возложены на ICMP, что заставит отделы информационной безопасности внимательнее относиться к данному протоколу, так как простое его запрещение уже стало невозможным. Мы не станем описывать все изменения, произошедшие с протоколом, так как читатель сможет с лёгкостью найти их на большинстве IT-ресурсов. Вместо этого покажем практические примеры настройки устройств на базе Cisco IOS для работы с IPv6.
Многие начинающие сетевые специалисты задаются вопросом: «Нужно ли сейчас начинать изучать IPv6?» На наш взгляд, сегодня уже нельзя подходить к IPv6 как к отдельной главе или технологии, вместо этого все изучаемые техники и методики следует отрабатывать сразу на обеих версиях протокола IP. Так, например, при изучении работы протокола динамической маршрутизации EIGRP стоит проводить настройку тестовых сетей в лаборатории как для IPv4, так и для IPv6 одновременно. Перейдём от слов к делу!
Адресация в IPv6
Длина адреса протокола IPv6 составляет 128 бит, что в четыре раза больше той, которая была в IPv4. Количество адресов IPv6 огромно и составляет 2128≈3,4•1038. Сам адрес протокола IPv6 можно разделить на две части: префикс и адрес хоста, который ещё называют идентификатором интерфейса. Такое деление очень похоже на то, что использовалось в IPv4 при бесклассовой маршрутизации.

Адреса в IPv6 записываются в шестнадцатеричной форме, каждая группа из четырёх цифр отделяется двоеточием. Например, 2001:1111:2222:3333:4444:5555:6666:7777. Маска указывается через слеш, то есть, например, /64. В адресе протокола IPv6 могут встречаться длинные последовательности нулей, поэтому предусмотрена сокращённая запись адреса. Во-первых, могут не записываться начальные нули каждой группы цифр, то есть вместо адреса 2001:0001:0002:0003:0004:0005:0006:7000 можно записать 2001:1:2:3:4:5:6:7000. Конечные нули при этом не удаляются. В случае, когда группа цифр в адресе (или несколько групп подряд) содержит только нули, она может быть заменена на двойное двоеточие. Например, вместо адреса 2001:1:0:0:0:0:0:1 может использоваться сокращённая запись вида 2001:1::1. Стоит отметить, что сократить адрес таким образом можно только один раз. Ниже приводятся правильные и неправильные формы записи IPv6 адресов.
Правильная запись.
2001:0000:0db8:0000:0000:0000:07a0:765d2001:0:db8:0:0:0:7a0:765d
2001:0:db8::7a0:765d
Ошибочная форма.
2001::db8::7a0:765d2001:0:db8::7a:765d
Забавные сокращения.
::/0 – шлюз по умолчанию::1 – loopback2001:2345:6789::/64 – адрес какой-то сетиОднако не все адреса протокола IPv6 могут быть назначены узлам в глобальной сети. Существует несколько зарезервированных диапазонов и типов адресов. Адрес IPv6 может относиться к одному из трёх следующих типов.
- Unicast
- Multicast
- Anycast
Адреса Unicast очень похожи на аналогичные адреса протокола IPv4, они могут назначаться интерфейсам сетевых устройств, серверам и хостам конечных пользователей. Групповые или Multicast адреса предназначены для доставки пакетов сразу нескольким получателям, входящим в группу. При использовании Anycast адресов данные будут получены ближайшим узлом, которому назначен такой адрес. Стоит обратить особое внимание на то, что в списке поддерживаемых протоколом IPv6 адресов отсутствуют широковещательные адреса. Даже среди Unicast адресов существует более мелкое дробление на типы.
- Link local
- Global unicast
- Unique local
Адреса, относящиеся к группе Unique local, описаны в RFC 4193 и по своему назначению очень похожи на приватные адреса протокола IPv4, описанные в RFC 1918. Адреса группы Link local предназначены для передачи информации между устройствами, подключёнными к одной L2-сети. Большинство адресов из диапазона Global unicast могут быть назначены интерфейсам конкретных сетевых узлов. Список зарезервированных адресов представлен ниже.
| IPv6 адрес | Длина префикса | Описание | Заметки |
| :: | 128 | - | Аналог 0.0.0.0 в IPv4 |
| ::1 | 128 | Loopback | Аналог 127.0.0.1 в IPv4 |
| ::xx.xx.xx.xx | 96 | Встроенный IPv4 | IPv4 совместимый. Устарел, не используется |
| ::ffff:xx.xx.xx.xx | 96 | IPv4, отображённый на IPv6 | Для хостов, не поддерживающих IPv6 |
| 2001:db8:: | 32 | Документирование | Зарезервирован для примеров. RFC 3849 |
| fe80:: - febf:: | 10 | Link-Local | Аналог 169.254.0.0/16 в IPv4 |
| fec0:: - feff:: | 10 | Site-Local | Аналог сетей 10.0.0.0, 172.16.0.0, 192.168.0.0. RFC 3879. Устарел. |
| fc00:: | 7 | Unique Local Unicast | Пришёл на смену Site-Local. RFC 4193 |
| ffxx:: | 8 | Multicast | - |
Базовая настройка интерфейсов
Включение маршрутизации IPv6 производится с помощью команды ipv6 unicast-routing. В принципе, поддержка маршрутизатором протокола IPv6 будет производиться и без введения указанной команды, однако без неё устройство будет выполнять функции хоста для IPv6. Многие команды, к которым вы привыкли в IPv4, присутствуют также и в IPv6, однако для них вместо опции ip нужно будет указывать слово ipv6.
Настройка адреса на интерфейсе возможна несколькими способами. При одном лишь включении поддержки IPv6 на интерфейсе автоматически назначается link-local адрес.
R1#conf t
Enter configuration commands, one per line. End with CNTL/Z.
R1(config)#int gi0/0
R1(config-if)#ipv6 enable
R1(config-if)#^Z
R1#show ipv6 int bri
Ethernet0/0 [administratively down/down]
unassigned
GigabitEthernet0/0 [up/up]
FE80::C800:3FFF:FED0:A008
Вычисление части адреса link-local производится с помощью алгоритма EUI-64 на основе MAC-адреса интерфейса. Для этого в середину 48 байтного МАС-адреса автоматически дописывается два байта, которые в шестнадцатеричной записи имеют вид FFFE, а также производится инвертирование седьмого бита первого байта MAC-адреса. На рисунках ниже схематично показана работа обсуждаемого алгоритма.
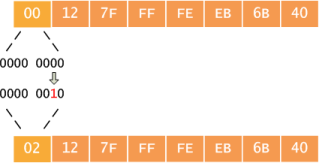
Сравните указанный выше link-local адрес с физическим адресом интерфейса Gi0/0 маршрутизатора (несущественная часть вывода команды sho int Gi0/0 удалена).
R1#show int gi0/0
GigabitEthernet0/0 is up, line protocol is up
Hardware is i82543 (Livengood), address is ca00.3fd0.a008 (bia ca00.3fd0.a008)
EUI-64 часть IPv6 адреса: C800:3FFF:FED0:A008.
Назначение адреса на интерфейс вручную производится с помощью команды ipv6 address, например, ipv6 address 2001:db8::1/64. Возможно лишь указывать адрес сегмента сети, оставшаяся часть будет назначаться автоматически с использованием преобразованного с помощью EUI-64 физического адреса интерфейса, для чего используйте команду с ключевым словом eui-64.
R2#conf t
R2(config)#int gi0/0
R2(config-if)#ipv ad 2001:db8::/64 eui-64
R2(config-if)#^Z
R2#show ipv6 int bri
Ethernet0/0 [administratively down/down]
unassigned
GigabitEthernet0/0 [up/up]
FE80::C801:42FF:FEA4:8
2001:DB8::C801:42FF:FEA4:8
Обмен сообщениями внутри одного L2-сегмента только с помощью адресов link-local возможен и в некоторых случаях используется, однако в большинстве ситуаций интерфейсу должен быть назначен обычный маршрутизируемый IPv6-адрес. Так, например, соседство по протоколам OSPF или EIGRP устанавливается с использованием link-local адресов. Автоматический поиск соседа и другие служебные протоколы также работают по link-local адресам.
R1#sho ipv6 int brief
Ethernet0/0 [administratively down/down]
unassigned
GigabitEthernet0/0 [up/up]
FE80::C800:42FF:FEA4:8
2001:DB8::1
R1#sho ipv ei ne
IPv6-EIGRP neighbors for process 1
H Address Interface Hold Uptime SRTT RTO Q Seq
(sec) (ms) Cnt Num
0 Link-local address: Gi0/0 12 00:01:03 39 234 0 3
FE80::C801:42FF:FEA4:8
R1#ping FE80::C801:42FF:FEA4:8
Output Interface: GigabitEthernet0/0
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to FE80::C801:42FF:FEA4:8, timeout is 2 seconds:
Packet sent with a source address of FE80::C800:42FF:FEA4:8
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 4/20/48 ms
Естественно, сохранилась и возможность автоматического назначения адреса в IPv6 с помощью протокола DHCP. Стоит, правда, отметить, что в IPv6 существует два различных типа DHCP: stateless и stateful, настройка которых производится с помощью команд ipv6 address autoconfig и ipv6 address dhcp соответственно.
Настройка «серверной» части практически не отличается от таковой для IPv4. Сначала требуется создать DHCP пул, после чего привязать его к интерфейсу. Привязка к интерфейсу осуществляется в явном виде с помощью интерфейсной команды ipv6 dhcp server name, где в качестве name выступает имя ранее созданного пула DHCP. Здесь же стоит отметить, что DHCPv6 не позволяет исключать определённые IPv6 адреса из диапазона так, как это делалось для IPv4 с помощью команды ip dhcp excluded-address, равно как и осуществлять ручную привязку адреса к клиенту.
ipv6 dhcp pool test
address prefix 2001:1::/64
dns-server 2001:1::1
domain-name foxnetwork.ru
interface GigabitEthernet1/0
no ip address
negotiation auto
ipv6 address 2001:1::1/64
ipv6 dhcp server test
ipv6 nd managed-config-flag
ipv6 nd other-config-flag
Команда ipv6 nd managed-config-flag указывает клиенту на необходимость использования DHCPv6 для получения адреса. Также можно уведомить клиента о необходимости получения дополнительных параметров (адрес DNS-сервера или имя домена) с помощью команды ipv6 nd other-config-flag.
Просмотреть информацию о настроенных пулах DHCPv6 можно с помощью команды show ipv6 dhcp pool.
R2#sho ipv dhcp pool
DHCPv6 pool: test
Address allocation prefix: 2001:1::/64 valid 172800 preferred 86400 (1 in use, 0 conflicts)
DNS server: 2001:1::1
Domain name: foxnetwork.ru
Active clients: 1
Список текущих клиентов отображается в выводе команды show ipv6 dhcp binding.
R2#show ipv6 dhcp binding
Client: FE80::C801:26FF:FEFC:1C
DUID: 00030001CA0126FC0008
Username : unassigned
IA NA: IA ID 0x00050001, T1 43200, T2 69120
Address: 2001:1::CDFD:B868:5AFF:F258
preferred lifetime 86400, valid lifetime 172800
expires at Mar 12 2015 08:56 AM (170469 seconds)
Сброс текущих привязок DHCPv6 производится с помощью команды clear ipv6 dhcp binding {* | ipv6-address}.
Вывод списка интерфейсов, на которых задействован протокол DHCPv6 производится с помощью команды show ipv6 dhcp interface.
R2#show ipv6 dhcp interface
GigabitEthernet1/0 is in server mode
Using pool: test
Preference value: 0
Hint from client: ignored
Rapid-Commit: disabled
Кроме stateful DHCPv6 оборудование Cisco поддерживает также версию DHCPv6 Lite, отличающуюся отсутствием команды address prefix внутри пула и интерфейсной опции managed-config-flag. В этом случае адрес интерфейса узла вычисляется на основе сообщения Router Advertisement.
ipv6 dhcp pool test
dns-server 2001:1::1
domain-name foxnetwork.ru
interface GigabitEthernet1/0
no ip address
negotiation auto
ipv6 address 2001:1::1/64
ipv6 dhcp server test
ipv6 nd other-config-flag
Также как и для IPv4 L3-коммутаторы и маршрутизаторы Cisco могут выполнять функции DHCP ретранслятора, для чего используется команда ipv6 dhcp relay destination ipv6-address, где ipv6-address – адрес сервера DHCPv6.
В DHCPv6 появилась очень интересная возможность – делегирование префиксов. Данная функция, на наш взгляд, будет наиболее востребована операторами связи, так как позволяет делегировать клиенту большой префикс для распределения внутри его корпоративной сети. Рассмотрим работу функции Prefix Delegation на примере. На схеме ниже маршрутизатор Delegating_router представляет оконечное оборудование оператора, CE_router – граничное оборудование клиента. Маршрутизаторы Client_net1 и Client_net2 эмулируют устройства, подключённые в разные IPv6-сети клиента. Стоит особо подчеркнуть, что Client_net1 и Client_net2 находятся в разных подсетях, между коммутатором SW1 и маршрутизатором CE_router поднят транк, в котором существуют две виртуальные сети №2 (для Client_net1) и №3 (для Client_net2). На маршрутизаторе CE_router для каждой виртуальной сети настраивается свой подынтерфейс.
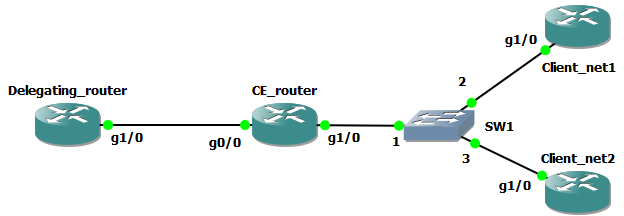
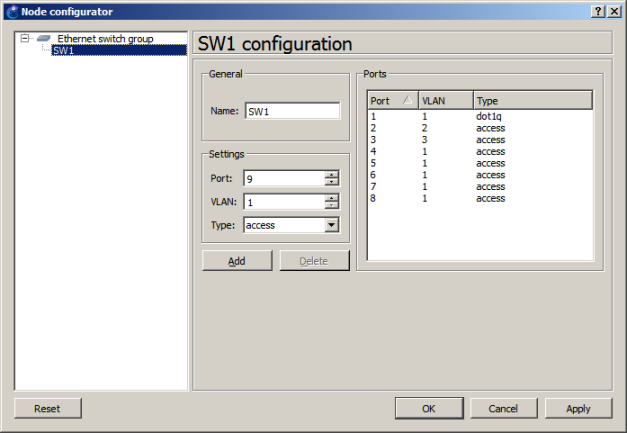
Первое, с чего следует начать настройку, - сконфигурировать адреса на канале между маршрутизаторами Delegating_router и CE_router.
Delegating_router(config)#int gi1/0
Delegating_router(config-if)#no sh
Delegating_router(config-if)#ipv6 address 2001:DB8:1::1/64
Delegating_router(config-if)#^Z
Delegating_router#
CE_router(config)#int gi0/0
CE_router(config-if)#no sh
CE_router(config-if)# ipv6 address 2001:DB8:1::2/64
CE_router(config-if)#^Z
CE_router#
На маршрутизаторе Delegating_router создадим локальный пул, из которого будет производиться раздача префиксов клиентам.
Delegating_router(config)#ipv6 local pool c_prefix 2001:DB8::/40 48
Пул c_prefix определён префиксом 2001:DB8::/40, из которого клиентам будут раздаваться меньшие префиксы с маской /48.
Вслед за локальным пулом необходимо создать пул DHCPv6, который привязать к интерфейсу Gi1/0.
Delegating_router(config)#ipv6 dhcp pool customers
Delegating_router(config-dhcpv6)# prefix-delegation pool c_prefix
Delegating_router(config-dhcpv6)#int gi1/0
Delegating_router(config-if)#ipv6 dhcp server customers
Настройка делегирующего маршрутизатора на этом завершается. На граничном маршрутизаторе клиента делегируемый префикс необходимо принять с помощью интерфейсной команды ipv6 dhcp client pd prefix, где prefix – имя принимаемого префикса, это имя будет использоваться в дальнейшем.
CE_router#sho run int gi0/0
Building configuration...
Current configuration : 170 bytes
interface GigabitEthernet0/0
no ip address
ipv6 address 2001:DB8:1::2/64
ipv6 dhcp client pd prefix
end
CE_router#sho ipv dhcp interface gi0/0
GigabitEthernet0/0 is in client mode
Prefix State is OPEN
Renew will be sent in 3d10h
Address State is IDLE
List of known servers:
Reachable via address: FE80::C801:2FF:FEC8:1C
DUID: 00030001CA0102C80008
Preference: 0
Configuration parameters:
IA PD: IA ID 0x00040001, T1 302400, T2 483840
Prefix: 2001:DB8::/48
preferred lifetime 604800, valid lifetime 2592000
expires at Apr 09 2015 10:39 AM (2587501 seconds)
Information refresh time: 0
Prefix name: prefix
Prefix Rapid-Commit: disabled
Address Rapid-Commit: disabled
Адреса клиентских подсетей будут назначаться из полученного префикса. Так как данному клиенту был выделен префикс 2001:DB8::/48, то адреса конечных сетей будут, например, такими 2001:DB8:0:1::/64 и 2001:DB8:0:2::/64. Произведём соответствующую настройку подынтерфейсов маршрутизатора CE_router. Как видно из приведённого ниже листинга, адреса не указываются в явном виде, вместо этого используется полученный ранее от провайдера префикс.
CE_router#sho run int gi1/0.2
Building configuration...
Current configuration : 97 bytes
interface GigabitEthernet1/0.2
encapsulation dot1Q 2
ipv6 address prefix ::1:0:0:0:1/64
end
CE_router#sho run int gi1/0.3
Building configuration...
Current configuration : 97 bytes
interface GigabitEthernet1/0.3
encapsulation dot1Q 3
ipv6 address prefix ::2:0:0:0:1/64
end
Единственное, что осталось сделать – получить адреса на клиентских узлах.
Client_net1#conf t
Enter configuration commands, one per line. End with CNTL/Z.
Client_net1(config)#int gi1/0
Client_net1(config-if)#no sh
*Mar 10 11:38:07.959: %LINK-3-UPDOWN: Interface GigabitEthernet1/0, changed state to up
*Mar 10 11:38:08.959: %LINEPROTO-5-UPDOWN: Line protocol on Interface GigabitEthernet1/0, changed state to up
Client_net1(config-if)#ipv6 address autoconfig
Client_net1(config-if)#exi
Client_net1(config)#exi
Client_net1#sho ipv int bri
GigabitEthernet1/0 [up/up]
FE80::C803:1EFF:FE3C:1C
2001:DB8:0:1:C803:1EFF:FE3C:1C
Client_net1#
Ещё одной возможностью, связанной с использованием префиксов, является опция глобального определения префикса для маршрутизатора. Такая возможность позволяет упростить процедуру назначения адресов на интерфейсы маршрутизатора или L3-коммутатора. Допустим, что организации выделена сеть 2001:db8:1::/48. Это означает, что все адреса будут начинаться с «2001:db8:1». Начать нужно с определения префикса.
R1(config)#ipv6 general-prefix ?
WORD General prefix name
R1(config)#ipv6 general-prefix fox ?
6rd 6rd
6to4 6to4
X:X:X:X::X/<0-128> IPv6 prefix
R1(config)#ipv6 general-prefix fox 2001:DB8:1::/48
R1(config)#do sho ipv gene
IPv6 Prefix fox, acquired via Manual configuration
2001:DB8:1::/48 Valid lifetime infinite, preferred lifetime infinite
После того, как префикс сконфигурирован, можно переходить к его непосредственному назначению на интерфейс.
R1(config)#int gi0/0
R1(config-if)#ipv address ?
WORD General prefix name
X:X:X:X::X IPv6 link-local address
X:X:X:X::X/<0-128> IPv6 prefix
autoconfig Obtain address using autoconfiguration
dhcp Obtain a ipv6 address using dhcp
R1(config-if)#ipv address fox ?
X:X:X:X::X/<0-128> IPv6 prefix
R1(config-if)#ipv address fox 0:0:0:1::1/64
R1(config-if)#^Z
R1#sho ipv int bri
Ethernet0/0 [administratively down/down]
GigabitEthernet0/0 [up/up]
FE80::C801:3CFF:FED0:8
2001:DB8:1:1::1
R1#sho run int gi0/0
Building configuration...
Current configuration : 144 bytes
interface GigabitEthernet0/0
no ip address
duplex full
speed 1000
media-type gbic
negotiation auto
ipv6 address fox ::1:0:0:0:1/64
end
Стоит обратить особое внимание на синтаксис, который используется при назначении адреса на интерфейс. Левая часть адреса заполняется битами из основного префикса (количество бит соответствует длине основного префикса). Оставшаяся часть берётся из указанного в команде ipv6 address адреса. В принципе, левая часть указываемого на интерфейсе адреса может быть любой, в примере выше она заполнена нулями.
Использование основного префикса может быть совмещено с автоматическим назначением адреса на интерфейс с помощью SLAAC.
R1#conf t
Enter configuration commands, one per line. End with CNTL/Z.
R1(config)#int e0/0
R1(config-if)#ipv add fox 0:0:0:2::/64 ?
anycast Configure as an anycast
cga Use CGA interface identifier
eui-64 Use eui-64 interface identifier
<cr>
R1(config-if)#ipv add fox 0:0:0:2::/64 eui-64
R1(config-if)#^Z
R1#sho ipv int bri
Ethernet0/0 [administratively down/down]
FE80::C801:3CFF:FED0:6
2001:DB8:1:2:C801:3CFF:FED0:6
GigabitEthernet0/0 [up/up]
FE80::C801:3CFF:FED0:8
2001:DB8:1:1::1
С помощью команды sho ipv general-prefix можно просмотреть, на каких интерфейсах сконфигурированы адреса, использующие определённый основной префикс.
R1#sho ipv general-prefix
IPv6 Prefix fox, acquired via Manual configuration
2001:DB8:1::/48 Valid lifetime infinite, preferred lifetime infinite
GigabitEthernet0/0 (Address command)
Ethernet0/0 (Address command)
Справедливости ради, стоит отметить, что допускается определить несколько префиксов с одним именем. На интерфейсы будут назначены все сконфигурированные адреса.
R1#sho run | i general
ipv6 general-prefix fox 2001:DB8:1::/48
ipv6 general-prefix fox 2001:DB8:2::/48
R1#sho ipv gene
IPv6 Prefix fox, acquired via Manual configuration
2001:DB8:1::/48 Valid lifetime infinite, preferred lifetime infinite
2001:DB8:2::/48 Valid lifetime infinite, preferred lifetime infinite
GigabitEthernet0/0 (Address command)
Ethernet0/0 (Address command)
R1#sho ipv int bri
Ethernet0/0 [administratively down/down]
FE80::C801:3CFF:FED0:6
2001:DB8:1:2:C801:3CFF:FED0:6
2001:DB8:2:2:C801:3CFF:FED0:6
GigabitEthernet0/0 [up/up]
FE80::C801:3CFF:FED0:8
2001:DB8:1:1::1
2001:DB8:2:1::1
Как уже было отмечено ранее, в IPv6 протокол ARP более не используется. Определение соседей производится с помощью протокола NDP (Neighbor Discovery Protocol) путём обмена сообщениями ICMP, отправляя их на групповой адрес FF02::1.
R1#show ipv6 neighbors
IPv6 Address Age Link-layer Addr State Interface
FE80::C801:42FF:FEA4:8 25 ca01.42a4.0008 STALE Gi0/0
В операционных системах семейства Windows также присутствует возможность просмотра списка соседей (аналог команды arp –a), правда, теперь придётся использовать более длинный системный вызов.
C:\>netsh interface ipv6 show neighbors
Interface 1: Loopback Pseudo-Interface 1
Internet Address Physical Address Type
-------------------------------------------- ----------------- -----------
ff02::c Permanent
ff02::16 Permanent
ff02::1:2 Permanent
ff02::1:3 Permanent
ff02::1:ff1e:f939 Permanent
Interface 24: Подключение по локальной сети 4
Internet Address Physical Address Type
-------------------------------------------- ----------------- -----------
2001:db8:0: 5::1 00-11-5c-1b-3d-49 Reachable (Router)
fe80::ffff:ffff:fffe Unreachable Unreachable
fe80::211:5cff:fe1b:3d49 00-11-5c-1b-3d-49 Stale (Router)
fe80::218:f3ff:fe73:33d7 Unreachable Unreachable
fe80::a541:1a9:3b2d:7734 Unreachable Unreachable
ff02::1 33-33-00-00-00-01 Permanent
ff02::2 33-33-00-00-00-02 Permanent
ff02::c 33-33-00-00-00-0c Permanent
ff02::16 33-33-00-00-00-16 Permanent
ff02::1:2 33-33-00-01-00-02 Permanent
ff02::1:3 33-33-00-01-00-03 Permanent
ff02::1:ff00:0 33-33-ff-00-00-00 Permanent
ff02::1:ff00:1 33-33-ff-00-00-01 Permanent
Похожим образом осуществляется поиск маршрутизаторов в локальном сегменте, правда, в этом случае отправка пакетов производится на адрес FF02::2. Заинтересованный узел отправляет сообщение RS (Router Solicitation), на которое получает ответ RA (Router Advertisement) от маршрутизатора. Указанный ответ содержит параметры работы IP-протокола в данной сети. Описанный процесс представлен на рисунке ниже.
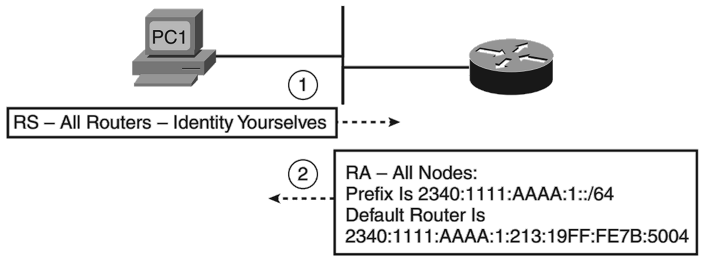
Обнаружение маршрутизатора, подключённого к сегменту локальной сети, используется для получения узлом адреса IPv6 с помощью процедуры stateless address autoconfiguration (SLAAC), которую ошибочно ещё называют Stateless DHCP.
Статические маршруты
Таблица маршрутизации протокола IPv6 по умолчанию содержит не только непосредственно подключённые сетки, но также и локальные адреса. Кроме того, в ней присутствует маршрут на групповые адреса.
R1#sho ipv6 routing
IPv6 Routing Table - Default - 3 entries
Codes: C - Connected, L - Local, S - Static, U - Per-user Static route
HA - Home Agent, MR - Mobile Router, R - RIP, I1 - ISIS L1
I2 - ISIS L2, IA - ISIS interarea, IS - ISIS summary, D - EIGRP
EX - EIGRP external
C 2001:DB8::/64 [0/0]
via GigabitEthernet0/0, directly connected
L 2001:DB8::1/128 [0/0]
via GigabitEthernet0/0, receive
L FF00::/8 [0/0]
via Null0, receive
Привычным способом задаются статические маршруты в IPv6. Единственное, что хотелось бы отметить, что при использовании link-local адресов, кроме самого адреса следующего перехода, необходимо указать и интерфейс.
R1#conf t
R1(config)#ipv ro ::/0 gi0/0 FE80::C801:42FF:FEA4:8
R1(config)#^Z
R1#sho ipv6 routing
IPv6 Routing Table - Default - 4 entries
Codes: C - Connected, L - Local, S - Static, U - Per-user Static route
HA - Home Agent, MR - Mobile Router, R - RIP, I1 - ISIS L1
I2 - ISIS L2, IA - ISIS interarea, IS - ISIS summary, D - EIGRP
EX - EIGRP external
S ::/0 [1/0]
via FE80::C801:42FF:FEA4:8, GigabitEthernet0/0
C 2001:DB8::/64 [0/0]
via GigabitEthernet0/0, directly connected
L 2001:DB8::1/128 [0/0]
via GigabitEthernet0/0, receive
L FF00::/8 [0/0]
via Null0, receive
Динамическая маршрутизация
Настройка динамической маршрутизации в IPv6 немногим сложнее. Во-первых, для добавления интерфейса в процесс маршрутизации команда network более не используется. Вместо этого на интерфейсе должна быть дана команда ipv6 eigrp 1 для включения EIGRP 1, либо ipv6 ospf 1 area 0 для добавления интерфейса в магистральную зону процесса OSPF 1. Процесс маршрутизации EIGRP для IPv6 по умолчанию выключен, поэтому его потребуется включить, но самой «приятной» особенностью является необходимость следить за назначением параметра router-id. При IPv4 маршрутизации данный параметр мог быть назначен вручную, либо выбран автоматически на основании IP-адресов, назначенных интерфейсам. Если на устройстве нет IPv4 адресов вовсе, то router-id для процессов динамической маршрутизации IPv6 может быть назначен только вручную.
Для элементарной сети, представленной на схеме ниже, проведём настройку EIGRP. Маршрутизатор R1 на интерфейсе Gi0/0 имеет адрес 2001:db8::1/64, R2 – 2001:db8::2/64.

Сначала настроим маршрутизатор R1.
R1#conf t
R1(config)#ipv6 router eigrp 1
R1(config-rtr)#no shut
R1(config-rtr)#eigrp router-id 1.1.1.1
R1(config-rtr)#int gi0/0
R1(config-if)#ipv6 eigrp 1
R1(config-if)#^Z
R1#sho ipv6 eigrp interfaces
EIGRP-IPv6 Interfaces for AS(1)
Xmit Queue PeerQ Mean Pacing Time Multicast Pending
Interface Peers Un/Reliable Un/Reliable SRTT Un/Reliable Flow Timer Routes
Gi0/0 0 0/0 0/0 0 0/0 0 0
R1#show ipv6 eigrp neighbors
EIGRP-IPv6 Neighbors for AS(1)
Введём аналогичные команды на R2, после это EIGRP-соседство устанавливается между двумя маршрутизаторами.
R1#
*Mar 21 12:01:13.763: %DUAL-5-NBRCHANGE: EIGRP-IPv6 1: Neighbor FE80::C80E:21FF:FEE4:8 (GigabitEthernet0/0) is up: new adjacency
R1#show ipv6 eigrp neighbors
EIGRP-IPv6 Neighbors for AS(1)
H Address Interface Hold Uptime SRTT RTO Q Seq
(sec) (ms) Cnt Num
0 Link-local address: Gi0/0 11 00:00:15 40 240 0 2
FE80::C80E:21FF:FEE4:8
На каждом из маршрутизаторов создадим интерфейс Loopback1, который будет эмулировать подключённые сети. На R1 интерфейсу Loopback1 назначим IPv6 адрес 2001:db8:1::1/64, на R2 – 2001:db8:2::1/64. Передать информацию о новых сетях в протокол динамической маршрутизации можно двумя способами: включить новый интерфейс в соответствующий протокол, либо выполнить перераспределение маршрутов (redistribute). Единственное, о чём следует помнить во втором случае, - о необходимости указания метрик. Метрика может быть указана либо в явном виде для каждого перераспределения, либо при помощи команды default-metric. Данное действие полностью аналогично IPv4, поэтому подробно останавливаться не будем.
Вывод с маршрутизатора R1.
R1#show ipv6 route
IPv6 Routing Table - default - 6 entries
Codes: C - Connected, L - Local, S - Static, U - Per-user Static route
B - BGP, R - RIP, H - NHRP, I1 - ISIS L1
I2 - ISIS L2, IA - ISIS interarea, IS - ISIS summary, D - EIGRP
EX - EIGRP external, ND - ND Default, NDp - ND Prefix, DCE - Destination
NDr - Redirect, O - OSPF Intra, OI - OSPF Inter, OE1 - OSPF ext 1
OE2 - OSPF ext 2, ON1 - OSPF NSSA ext 1, ON2 - OSPF NSSA ext 2, l - LISP
C 2001:DB8::/64 [0/0]
via GigabitEthernet0/0, directly connected
L 2001:DB8::1/128 [0/0]
via GigabitEthernet0/0, receive
C 2001:DB8:1::/64 [0/0]
via Loopback1, directly connected
L 2001:DB8:1::1/128 [0/0]
via Loopback1, receive
EX 2001:DB8:2::/64 [170/2560512]
via FE80::C80E:21FF:FEE4:8, GigabitEthernet0/0
L FF00::/8 [0/0]
via Null0, receive
R1#sho run int loo 1
Building configuration...
Current configuration : 87 bytes
interface Loopback1
no ip address
ipv6 address 2001:DB8:1::1/64
ipv6 eigrp 1
end
R1#sho run | sec router
ipv6 router eigrp 1
eigrp router-id 1.1.1.1
Вывод с маршрутизатора R2.
R2#show ipv6 route
IPv6 Routing Table - default - 6 entries
Codes: C - Connected, L - Local, S - Static, U - Per-user Static route
B - BGP, R - RIP, H - NHRP, I1 - ISIS L1
I2 - ISIS L2, IA - ISIS interarea, IS - ISIS summary, D - EIGRP
EX - EIGRP external, ND - ND Default, NDp - ND Prefix, DCE - Destination
NDr - Redirect, O - OSPF Intra, OI - OSPF Inter, OE1 - OSPF ext 1
OE2 - OSPF ext 2, ON1 - OSPF NSSA ext 1, ON2 - OSPF NSSA ext 2, l - LISP
C 2001:DB8::/64 [0/0]
via GigabitEthernet0/0, directly connected
L 2001:DB8::2/128 [0/0]
via GigabitEthernet0/0, receive
D 2001:DB8:1::/64 [90/130816]
via FE80::C80D:1EFF:FE28:8, GigabitEthernet0/0
C 2001:DB8:2::/64 [0/0]
via Loopback1, directly connected
L 2001:DB8:2::1/128 [0/0]
via Loopback1, receive
L FF00::/8 [0/0]
via Null0, receive
R2#sho run int lo 1
Building configuration...
Current configuration : 73 bytes
interface Loopback1
no ip address
ipv6 address 2001:DB8:2::1/64
end
R2#sho run | sec router
ipv6 router eigrp 1
eigrp router-id 2.2.2.2
redistribute connected
default-metric 1000 1 100 100 1500
Если в сети используется протокол BGP, то для управления им придётся воспользоваться несколько иным подходом: в BGP не создаются различные процессы для IPv4 и IPv6. Вместо этого внутри одного «родительского» процесса деление на версии протокола IP производится с помощью команды address-family. Ниже приводится вывод с маршрутизатора R1. Настройка R2 выполнена аналогично.
R1#show run | sec router bgp
router bgp 65001
bgp router-id 1.1.1.1
bgp log-neighbor-changes
neighbor 2001:DB8::2 remote-as 65002
!
address-family ipv4
no neighbor 2001:DB8::2 activate
exit-address-family
!
address-family ipv6
network 2001:DB8:1::/64
neighbor 2001:DB8::2 activate
exit-address-family
R1#show bgp ipv6 summary
BGP router identifier 1.1.1.1, local AS number 65001
BGP table version is 3, main routing table version 3
2 network entries using 336 bytes of memory
2 path entries using 208 bytes of memory
2/2 BGP path/bestpath attribute entries using 272 bytes of memory
1 BGP AS-PATH entries using 24 bytes of memory
0 BGP route-map cache entries using 0 bytes of memory
0 BGP filter-list cache entries using 0 bytes of memory
BGP using 840 total bytes of memory
BGP activity 2/0 prefixes, 2/0 paths, scan interval 60 secs
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
2001:DB8::2 4 65002 12 12 3 0 0 00:07:24 1
% NOTE: This command is deprecated. Please use 'show bgp ipv6 unicast'
R1#show bgp ipv6 unicast summary
BGP router identifier 1.1.1.1, local AS number 65001
BGP table version is 3, main routing table version 3
2 network entries using 336 bytes of memory
2 path entries using 208 bytes of memory
2/2 BGP path/bestpath attribute entries using 272 bytes of memory
1 BGP AS-PATH entries using 24 bytes of memory
0 BGP route-map cache entries using 0 bytes of memory
0 BGP filter-list cache entries using 0 bytes of memory
BGP using 840 total bytes of memory
BGP activity 2/0 prefixes, 2/0 paths, scan interval 60 secs
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
2001:DB8::2 4 65002 12 12 3 0 0 00:07:34 1
R1#show bgp ipv6 unicast
BGP table version is 3, local router ID is 1.1.1.1
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
*> 2001:DB8:1::/64 :: 0 32768 i
*> 2001:DB8:2::/64 2001:DB8::2 0 0 65002 i
На момент написания статьи (конец марта 2014 года) в глобальной таблице маршрутизации (BGP full view или BGP full table) насчитывалось примерно 500000 префиксов для IPv4 и около 17000 записей для IPv6.
Конфигурирование протокола OSPF для работы в сети IPv6 производится схожим образом. Протокол, который надо включать и настраивать, называется OSPFv3. Он полностью независим от IPv4. Третья версия протокола содержит ряд изменений и дополнений по сравнению с предыдущей реализацией OSPF.
interface GigabitEthernet0/0
no ip address
media-type gbic
speed 1000
duplex full
negotiation auto
ipv6 enable
ipv6 ospf 1 area 0
router ospfv3 1
router-id 1.1.1.1
address-family ipv6 unicast
redistribute connected
exit-address-family
Списки доступа
В списках доступа также есть небольшие изменения. Так, например, установка листа на интерфейс производится командой ipv6 traffic-filter, например, ipv6 traffic-filter TEST in.
R2#show run | section access
ipv6 access-list TEST
deny icmp any any echo-reply
deny icmp any any echo-request
permit ipv6 any any
R2#show ipv6 access-list
IPv6 access list test
deny icmp any any echo-reply sequence 10
deny icmp any any echo-request (5 matches) sequence 20
permit ipv6 any any (28 matches) sequence 30
interface GigabitEthernet0/0
no ip address
media-type gbic
speed 1000
duplex full
negotiation auto
ipv6 address 2001:DB8::2/64
ipv6 eigrp 1
ipv6 traffic-filter TEST in
После установки листа TEST на интерфейс Gi0/0 в приведённой выше схеме маршрутизатор R2 перестаёт отвечать на эхо-запросы по протоколу ICMP.
R1#ping 2001:db8::2
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 2001:DB8::2, timeout is 2 seconds:
AAAAA
Success rate is 0 percent (0/5)
Туннелирование в среде IPv4 и IPv6
Не менее интересный вопрос связан с работой туннелей, поддерживающих IPv6. Самыми простыми туннелями в среде IPv4 были IPIP (IP-in-IP) и GRE. При использовании GRE с введением IPv6 для администратора практически ничего не меняется, однако поддержки IPv6 в IPIP нет. Вместо IPIP можно использовать IPv6IP. Приятной возможностью GRE является его универсальность, благодаря которой можно переносить протоколы IPv4 и IPv6 как поверх транспортной сети с IPv4, так и поверх сети IPv6. За выбор протокола транспортной сети отвечают ключевые слова ip или ipv6 после команды tunnel mode gre.
Вернёмся к нашей схеме и настроим между двумя маршрутизаторами туннель GRE так, чтобы поверх него работал протокол IPv4, а сам туннель существовал в сети IPv6. Листинг ниже представляет настройку туннельного интерфейса маршрутизатора R1. Устройство R2 конфигурируется аналогично.
R1#sho run int tunnel 1
Building configuration...
Current configuration : 180 bytes
interface Tunnel1
ip address 192.168.0.1 255.255.255.252
tunnel source GigabitEthernet0/0
tunnel mode gre ipv6
tunnel destination 2001:DB8::2
tunnel path-mtu-discovery
end
R1#ping 192.168.0.2
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 192.168.0.2, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 48/87/120 ms
На сегодняшний день, скорее всего, администратор столкнётся с противоположной ситуацией: потребуется передавать IPv6 трафик поверх сети IPv4. Конфигурация в этом случае симметрична: настройки IPv4 и IPv6 меняются местами. Пожалуй, стоит ещё отметить, что на данный момент в туннелях GRE поверх IPv6 отсутствует поддержка keepalive сообщений.
Кроме перечисленных туннелей существует ещё несколько распространённых типов: 6to4, 6in4, 6rd, Teredo, ISATAP, однако их рассмотрение выходит далеко за рамки данного материала. Сосуществование сетей IPv4 и IPv6 может происходить по одному из трёх сценариев: использование разнообразных туннелей, о которых упоминалось выше, в режиме dual stack, при котором всеми устройствами одновременно поддерживаются обе версии протокола IP, либо при помощи трансляций, например, NAT-PT.
Виртуальные процессы маршрутизации (VRF)
Ещё одна тема, которой хотелось бы коснуться в рамках беглого рассмотрения IPv6 – VRF. Конфигурирование VRF в многопротокольной среде производится немного иначе – без указания ключевого ip в начале. Здесь также используется подход с конструкцией address-family, который мы видели при настройке BGP. При создании VRF используется ключевое слово definition.
R1#conf t
R1(config)#vrf definition test
R1(config-vrf)#rd 1:1
VPN Routing/Forwarding instance configuration commands:
address-family Enter Address Family command mode
default Set a command to its defaults
description VRF specific description
exit Exit from VRF configuration mode
no Negate a command or set its defaults
rd Specify Route Distinguisher
route-target Specify Target VPN Extended Communities
vnet Virtual NETworking configuration
vpn Configure VPN ID as specified in rfc2685
R1(config-vrf)#address-family ?
ipv4 Address family
ipv6 Address family
R1(config-vrf)#address-family ipv6
R1(config-vrf-af)#?
IP VPN Routing/Forwarding instance configuration commands:
default Set a command to its defaults
exit-address-family Exit from vrf address-family configuration submode
export VRF export
import VRF import
inter-as-hybrid Inter AS hybrid mode
maximum Set a limit
mdt Backbone Multicast Distribution Tree
no Negate a command or set its defaults
protection Configure local repair
route-target Specify Target VPN Extended Communities
snmp Modify snmp parameters
R1(config-vrf-af)#^Z
R1#conf t
R1(config-if)#int loo 2
R1(config-if)#vrf forwarding test
R1(config-if)#^Z
R1#sho vrf
Name Default RD Protocols Interfaces
test 1:1 ipv6 Lo2
Добавление протокола маршрутизации в VRF производится также с использованием опции address-family. Добавить в VRF можно не только поименованные процессы, но и пронумерованные.
R1#sho run | sec router
router eigrp test
address-family ipv6 unicast vrf test autonomous-system 1
topology base
exit-af-topology
eigrp router-id 1.1.1.1
exit-address-family
R1#sho run int gi0/0
interface GigabitEthernet0/0
vrf forwarding test
no ip address
media-type gbic
speed 1000
duplex full
negotiation auto
ipv6 address 2001:DB8::1/64
end
R1#sho ipv route vrf test
IPv6 Routing Table - test - 4 entries
Codes: C - Connected, L - Local, S - Static, U - Per-user Static route
B - BGP, R - RIP, H - NHRP, I1 - ISIS L1
I2 - ISIS L2, IA - ISIS interarea, IS - ISIS summary, D - EIGRP
EX - EIGRP external, ND - ND Default, NDp - ND Prefix, DCE - Destination
NDr - Redirect, O - OSPF Intra, OI - OSPF Inter, OE1 - OSPF ext 1
OE2 - OSPF ext 2, ON1 - OSPF NSSA ext 1, ON2 - OSPF NSSA ext 2, l - LISP
C 2001:DB8::/64 [0/0]
via GigabitEthernet0/0, directly connected
L 2001:DB8::1/128 [0/0]
via GigabitEthernet0/0, receive
D 2001:DB8:2::/64 [90/2570240]
via FE80::C80E:21FF:FEE4:8, GigabitEthernet0/0
L FF00::/8 [0/0]
via Null0, receive
R1#sho eigrp address-family ipv6 vrf test neighbors
EIGRP-IPv6 VR(test) Address-Family Neighbors for AS(1)
VRF()
H Address Interface Hold Uptime SRTT RTO Q Seq
(sec) (ms) Cnt Num
0 Link-local address: Gi0/0 10 00:01:53 56 336 0 3
FE80::C80E:21FF:FEE4:8
Фрагментация
В литературе можно нередко встретить упоминания о том, что в IPv6 фрагментация невозможна. Действительно, если внимательно посмотреть на заголовок пакетов IPv6, можно обнаружить, что в нём нет полей, отвечающих за процедуру фрагментации. На рисунке ниже представлено сравнение заголовков пакетов IPv4 и IPv6. Тёмно-серым отмечены изменившиеся поля.
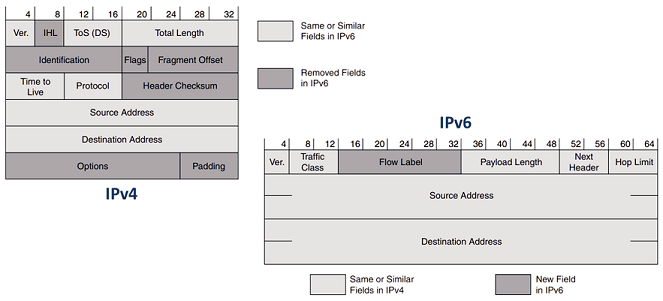
Как видно из представленного выше сравнения, поля Identification, Flags и Fragment Offset были удалены.
Проведём небольшой эксперимент, для чего соберём схему, представленную ниже.

Маршрутизаторы используют следующие адреса на своих интерфейсах со стандартной маской /64.
| Маршрутизатор и интерфейс | Адрес |
| R1 Gi0/0 | 2001:db8:12::1 |
| R2 Gi0/0 | 2001:db8:12::2 |
| R2 Gi1/0 | 2001:db8:23::2 |
| R3 Gi1/0 | 2001:db8:23::3 |
Сначала удостоверимся, что в IPv6 заголовке на самом деле отсутствуют указанные выше поля, для чего с помощью ICMP протокола убедимся в наличии связности между маршрутизаторами R1 и R3 и изучим содержимое одного из перехваченных на линке R1-R2 пакетов.
R1#ping 2001:db8:23::3
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 2001:DB8:23::3, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 8/14/16 ms
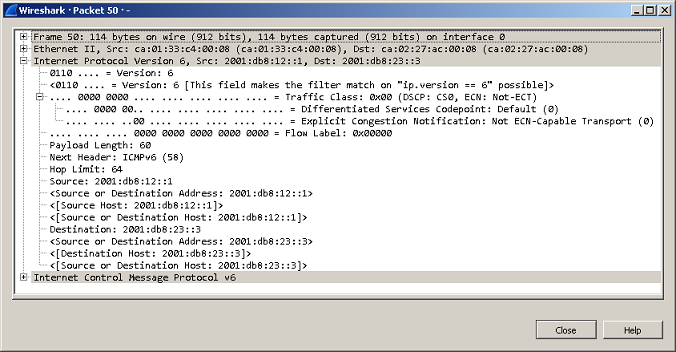
Выясним теперь значение MTU для интерфейса Gi0/0 маршрутизатора R1.
R1#sho ipv int gi0/0
GigabitEthernet0/0 is up, line protocol is up
IPv6 is enabled, link-local address is FE80::C801:33FF:FEC4:8
No Virtual link-local address(es):
Global unicast address(es):
2001:DB8:12::1, subnet is 2001:DB8:12::/64
Joined group address(es):
FF02::1
FF02::2
FF02::1:FF00:1
FF02::1:FFC4:8
MTU is 1500 bytes
ICMP error messages limited to one every 100 milliseconds
ICMP redirects are enabled
ICMP unreachables are sent
ND DAD is enabled, number of DAD attempts: 1
ND reachable time is 30000 milliseconds (using 30000)
ND advertised reachable time is 0 (unspecified)
ND advertised retransmit interval is 0 (unspecified)
ND router advertisements are sent every 200 seconds
ND router advertisements live for 1800 seconds
ND advertised default router preference is Medium
Hosts use stateless autoconfig for addresses.
Так как значение MTU для протокола IPv6 равно 1500 байт, то мы не сможем передать ICMP сообщения большего размера. Для того, чтобы это проверить, отправим с помощью команды ping несколько сообщений echo request размером 2000 байт.
R1#ping 2001:db8:23::3 si
R1#ping 2001:db8:23::3 size 2000
Type escape sequence to abort.
Sending 5, 2000-byte ICMP Echos to 2001:DB8:23::3, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 32/32/36 ms
Удивительно, не так ли?! Заглянем в дамп и выясним, что же происходит в сети на самом деле.
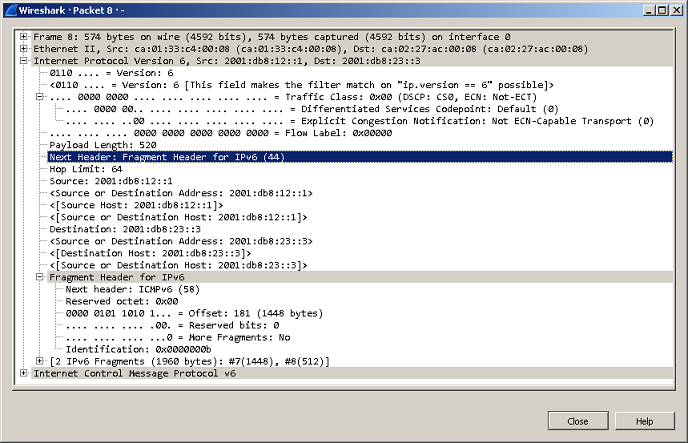
В представленном выше пакете IPv6 появился дополнительный заголовок Fragment Header for IPv6, которого не было ранее. Этот дополнительный заголовок и содержит такие важные для процесса фрагментации поля как: Offset, More Fragments и Identification. Таким образом, фрагментация в IPv6 всё-таки возможна и выполняется она отправителем с использованием вспомогательного заголовка Fragment Header for IPv6.
Стоит заметить, что в IPv6 заголовок пакета имеет строго фиксированную длину в 40 байт, а все вспомогательные опции вынесены в последующие заголовки. Данный подход носит название IPv6 header chain. Обратите внимание на значения поля Next Header в заголовке пакета IPv6 и последующем заголовке Fragment Header for IPv6.
Продолжим наши эксперименты и вручную уменьшим значение MTU для маршрутизатора R2 на линке R2-R3.
R2#conf t
Enter configuration commands, one per line. End with CNTL/Z.
R2(config)#int gi1/0
R2(config-if)#ipv mtu ?
<1280-1500> MTU (bytes)
R2(config-if)#ipv mtu 1300
R2(config-if)#do sho ipv int gi1/0 | i MTU
MTU is 1300 bytes
Теперь вновь сгенерируем на маршрутизаторе R1 несколько больших пакетов.
R1#ping 2001:db8:23::3 size 2000
Type escape sequence to abort.
Sending 5, 2000-byte ICMP Echos to 2001:DB8:23::3, timeout is 2 seconds:
B!!!!
Success rate is 80 percent (4/5), round-trip min/avg/max = 28/33/36 ms
Первый пакет был потерян, зато все остальные оказались успешно доставленными. Заглянем теперь в дамп трафика. Итак, маршрутизатор R1 сразу же выполняет фрагментацию и отправляет два пакета с размерами 1496 и 560 байт (на картинке ниже поле Length отображает длину кадра Ethernet, заголовок которого составляет 14 байт).
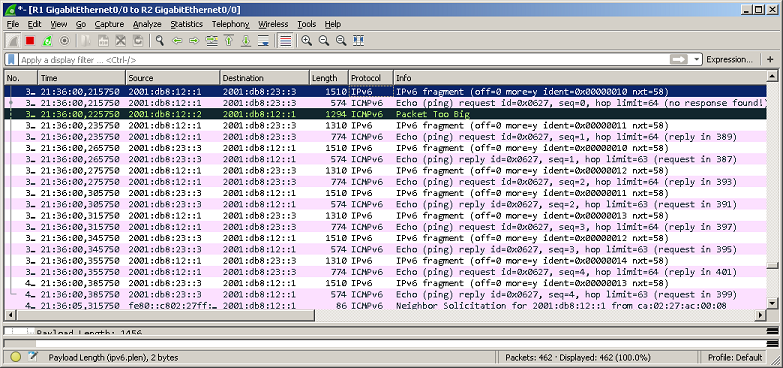
Однако первый пакет не может быть передан через линк R2-R3, о чём маршрутизатор R2 генерирует ICMP сообщение Packet Too Big (Type=2, Code=0). Маршрутизатор R1 реагирует на полученное ICMP-сообщение и начинает отправку данных, используя более мелкие пакеты: 1296 и 760 байт.
Да, протокол IPv4 ведёт себя совершенно иначе: маршрутизатор по пути следования трафика будет просто фрагментировать проходящие IP-пакеты без установленного бита DF, если их размер превышает значение MTU для исходящего интерфейса; и отбрасывать IP-пакеты с установленным битом DF в том же случае. Конечно, промежуточный маршрутизатор будет генерировать ICMP сообщение (Type=2, Code=4) Destination Unreachable (Fragmentation Needed), но отправляющая сторона никак не сможет на них отреагировать из-за выставленного бита DF.
В заключение хотели бы обратить внимание читателя на размеры IPv6 пакетов, которые получались при фрагментации для передачи через канал с IPv6 MTU равным 1300 байт. Пакеты имели размеры 1296 и 760 байт. Но почему именно 1296, а не 1300 байт? Ответ кроется в деталях реализации процедуры фрагментации, а именно в размере поля Offset заголовка Fragment Header for IPv6. Дело в том, что поле Offset имеет длину равную 13 бит и указывает на количество блоков по 8 байт, на которое смещён данный фрагмент. Таким образом, смещение фрагмента должно быть кратным 8 байтам. Аналогичная ситуация наблюдается и в протоколе IPv4, где поле Fragment Offset имеет абсолютно такую же длину.
Заключение
Завершая этот вводный кусочек, хочется отметить следующее.
- Администраторам стало сложнее запоминать адресацию своих сетей.
- Требуется освоиться с длиннющей записью сетей/хостов в IPv6.
- Нужно привыкнуть и освоить автоматический поиск и исследование соседей (маршрутизаторов и конечных станций), смириться с отсутствием широковещания.
- Наличие канальной информации об узле сразу в IP-адресе. Протокол ARP (или аналоги) в большинстве случаев более не требуется – вполне достаточно использования EUI-64 для определения хоста.
- Не так страшен черт, как его малюют: IP и есть IP – идеологически все очень близко, замена транспорта не существенно влияет на идеологию современных сетей передачи данных.
- Использование в IPv6 трансляции сетевых адресов NAT/PAT, довольно ресурсоёмкой операции, в большинстве ситуаций более не требуется.
- В сети могут существовать несколько хостов с абсолютно идентичными валидными маршрутизируемыми IPv6 адресами. Это так называемый anycast. Также стоит привыкнуть к наличию на разных интерфейсах маршрутизаторов адресов из одной и той же подсети не маршрутизируемых link-local адресов.
- Можно постепенно мигрировать от IPv4 к IPv6, либо поддерживать оба протокола в течение времени, необходимого на глобальный переход к IPv6.
- Компания Cisco и другие производители сетевого оборудования уже давно готовы к переходу на IPv6. Дело за администраторами.
Страница 3 из 8